Como construir pipelines de dados confiáveis com Delta Live Tables e Arquitetura Medallion
Delta Live Tables simplifica pipelines confiáveis no Databricks com Arquitetura Medallion. Tutorial com Bronze, Silver, Gold e qualidade de dados.

Criando seu primeiro Pipeline de Dados com Medallion Architecture e Delta Live Tables (DLT)
Aprenda a construir um pipeline de dados robusto utilizando DLT, a arquitetura Medallion e governança via Unity Catalog no Databricks.
O Delta Live Tables (DLT) é o framework declarativo do Databricks para construção de pipelines de dados confiáveis, escaláveis e observáveis. Diferente de abordagens tradicionais baseadas em notebooks agendados ou scripts SQL isolados, o DLT foi projetado para resolver um problema comum em ambientes analíticos: a complexidade operacional de manter pipelines de dados consistentes ao longo do tempo.
Em projetos de engenharia de dados, é comum começar com transformações simples utilizando tabelas Delta e jobs do Databricks. No entanto, à medida que o volume de dados cresce e os pipelines se tornam mais críticos, surgem desafios como controle de dependências, tratamento de falhas, validação de qualidade dos dados, versionamento de schemas e observabilidade do fluxo ponta a ponta.
É nesse contexto que o DLT se torna a escolha mais adequada. Ao adotar uma abordagem declarativa, o engenheiro de dados descreve o estado desejado dos dados por exemplo, quais tabelas devem existir, suas regras de qualidade e suas dependências, enquanto o Databricks se encarrega automaticamente da orquestração, do gerenciamento de infraestrutura, do monitoramento e da recuperação em caso de falhas.
Recentemente integrado ao Databricks Lakeflow como parte dos Declarative Pipelines, o DLT se posiciona como a solução ideal para pipelines contínuos ou recorrentes que exigem confiabilidade, governança e facilidade de manutenção. Ele não substitui completamente outras formas de criação de tabelas no Databricks, mas se destaca em cenários onde a previsibilidade, a qualidade dos dados e a observabilidade são requisitos essenciais.
Neste artigo, exploramos como utilizar o Delta Live Tables para construir pipelines de dados bem estruturados, demonstrando na prática como ele pode ser integrado a processos de ingestão externos e utilizado como camada central de transformação dentro do Databricks.
Unity Catalog e Governança Unificada
Diferente de arquiteturas legadas que dependiam do DBFS, os pipelines modernos operam sob o Unity Catalog (UC). O UC oferece:
Governança Unificada: Controle de acesso centralizado e linhagem de dados automática.
Volumes vs. Tabelas: O Unity Catalog diferencia arquivos brutos (Volumes) de dados processados registrados como tabelas gerenciadas.
Isolamento: Facilidade em separar ambientes de
dev,stagingeproddentro do mesmo metastore.
O que é a Arquitetura Medallion?
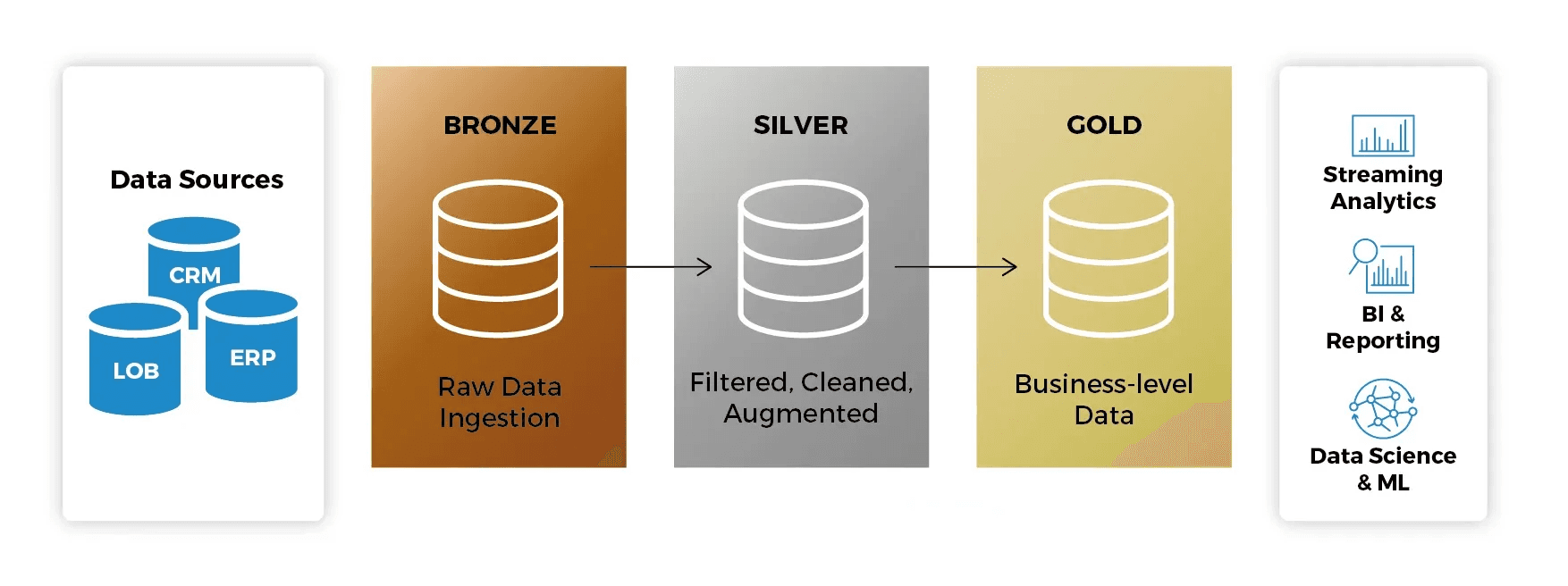
A arquitetura Medallion descreve uma série de camadas de dados que denotam a qualidade dos dados armazenados no Lakehouse:
Bronze: A camada de pouso (landing zone). Os dados são mantidos em seu formato original, permitindo o reprocessamento se necessário.
Silver: Os dados são limpos, normalizados e validados. Aqui, aplicamos as Expectations (regras de qualidade).
Gold: Camada final, com dados agregados e prontos para o consumo por analistas de BI e modelos de Machine Learning.
Ao usar o DLT dentro do ecossistema Lakeflow, você ganha observabilidade nativa: o Databricks gera automaticamente o gráfico de linhagem (lineage) e monitora a saúde do pipeline sem que você precise configurar ferramentas externas.
Por que usar Delta Live Tables?
Gerenciamento de Infraestrutura: O Databricks escala automaticamente os recursos computacionais.
Qualidade de Dados Nativa: Defina expectativas (Expectations) para impedir que dados corrompidos cheguem às camadas finais.
Linhagem Automática: Visualize como os dados fluem da origem até o consumo final.
Suporte a Streaming e Batch: Processe dados em tempo real ou em lotes usando a mesma sintaxe SQL ou Python.
Para este guia, utilizaremos SQL, que é a linguagem mais comum para transformações analíticas no Databricks, mas o DLT também suporta Python integralmente.
Conhecimento Assumido
Para tirar o máximo proveito deste tutorial, certifique-se de compreender:
Conceitos básicos de SQL.
O conceito de Arquitetura Medallion.
Navegação básica no Workspace do Databricks.
Pré-requisitos: Preparando a Fonte de Dados (MongoDB)
Antes de iniciar o pipeline de dados no Databricks, precisamos de uma fonte de dados operacional. Neste tutorial, utilizaremos o MongoDB Atlas Free Tier como banco de dados de origem, simulando um cenário real de dados transacionais.
Criando um Cluster MongoDB Free Tier
Para criar um cluster gratuito no MongoDB, siga o tutorial oficial da MongoDB:
Deploy de um cluster Free Tier:
https://www.mongodb.com/pt-br/docs/atlas/tutorial/deploy-free-tier-cluster/
Guia de primeiros passos:
Após a criação do cluster, certifique-se de:
Criar um usuário de banco de dados
Liberar o IP de acesso (ou permitir acesso de qualquer IP para fins de teste)
Copiar a string de conexão
Passo 1: Preparar os Dados de Origem
Neste guia, os dados de origem não são acessados diretamente pela Databricks via conectores nativos ou Auto Loader. Em vez disso, utilizamos a Erathos como camada de ingestão, simulando um cenário real de arquitetura moderna onde a ingestão e transformação são responsabilidades bem definidas.
A Erathos é uma ferramenta de ingestão de dados que permite conectar diferentes fontes (bancos de dados, APIs e sistemas externos) e entregar esses dados diretamente no Lakehouse, abstraindo a complexidade de:
Autenticação
Extração incremental
Agendamento
Monitoramento
Escrita em Delta Lake
Conectando o MongoDB à Erathos
A Erathos possui um conector nativo para MongoDB Atlas.
Documentação do conector MongoDB:
Criação e gerenciamento de conexões:
Neste passo, você irá:
Criar uma conexão com o MongoDB Atlas utilizando a string de conexão
Selecionar a collection desejada
Definir o modo de sincronização (full ou incremental)
Configurando o Databricks como Destino
Após configurar a fonte, definimos o Databricks como destino dos dados.
A Erathos oferece integração direta com Databricks + Unity Catalog, garantindo que os dados já cheguem governados ao Lakehouse.
Documentação oficial:
Neste passo, você irá:
Informar o workspace Databricks
Selecionar o catálogo e o schema de destino
Persistir os dados como tabelas Delta
Resultado da Ingestão
Para este tutorial, a Erathos foi utilizada para:
Conectar-se a um banco de dados MongoDB (demo)
Ingerir a collection:
theaters(1.564 registros)
Persistir os dados como tabelas Delta no Databricks, dentro de um schema governado pelo Unity Catalog
A partir desse ponto, todo o processamento e transformação dos dados será realizado exclusivamente via Delta Live Tables, mantendo o foco deste artigo na camada de transformação e qualidade dos dados.
Governança e Organização dos Dados
Antes de iniciar o pipeline DLT, é fundamental garantir que o Schema de destino já exista no Unity Catalog. O DLT segue estritamente a hierarquia:
Catalog > Schema > Table
Sem um schema previamente criado, o pipeline não conseguirá registrar corretamente os metadados nem expor as tabelas para consumo externo.
Nota: Em um cenário real, a Erathos poderia estar ingerindo dados a partir de bancos transacionais, APIs ou sistemas de terceiros, entregando-os diretamente em um catálogo governado no Databricks.
Estratégias de Ingestão: Batch vs. Streaming
Antes de codificarmos nossa primeira camada, é importante entender como o DLT consome diferentes tipos de fontes. Independentemente de os dados terem sido ingeridos via Erathos, Auto Loader ou outro mecanismo, o DLT oferece suporte tanto a processamento em batch quanto streaming.
Auto Loader: Utilizado para ingerir arquivos brutos de forma incremental usando
cloud_files. Esta é a forma mais comum. Você aponta para uma pasta no Cloud Storage (S3, ADLS, GCS) ou um Unity Catalog Volume.Como funciona: O Databricks monitora a chegada de novos arquivos (JSON, CSV, Parquet) e processa apenas os novos.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json")
Via Delta Table (Stream from Table): Se a sua origem já for uma Tabela Delta (e não apenas arquivos soltos), ela precisa suportar o histórico de mudanças (Change Data Feed).
Como funciona: Você lê a tabela como um fluxo contínuo.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table)
Nota de Implementação: Neste guia, os dados de
theatersforam ingeridos previamente via Erathos e persistidas como tabelas Delta estáticas. Por esse motivo, utilizaremos o comandoLIVE TABLE(batch). Ainda assim, a arquitetura Medallion permanece a mesma, podendo ser facilmente adaptada para fontes incrementais ou streaming.
Pré-requisitos Técnicos no Databricks
Workspace Databricks com Unity Catalog habilitado.
Permissões para criar pipelines DLT e escrever em um esquema no seu catálogo.
Passo 2: Criar o Notebook de Transformação
1. No seu Workspace, clique em New > Notebook. 2. Dê o nome de dlt_medallion_pipeline. 3. Certifique-se de que a linguagem padrão seja SQL.
As definições de tabelas no Delta Live Tables são declarativas e residem em notebooks SQL ou Python. Cada comando CREATE OR REFRESH LIVE TABLE descreve o que a tabela deve ser, enquanto o Databricks gerencia automaticamente como os dados são processados, versionados e otimizados dentro do pipeline.
Camada Bronze
A camada Bronze representa o ponto de entrada dos dados no nosso Lakehouse. Neste cenário, os dados já foram ingeridos no Databricks através da Erathos, que é responsável pela extração e sincronização incremental da fonte de dados.
O objetivo principal da Bronze é a fidelidade: capturamos os dados com o mínimo de transformações possíveis, preservando o formato original, incluindo campos JSON para garantir rastreabilidade e permitir reprocessamentos futuros.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM
Camada Silver
A camada Silver é onde a densidade técnica aumenta. Aqui realizamos a estruturação dos dados, a aplicação de regras de qualidade e a normalização de campos complexos, como JSONs, transformando dados brutos em um formato confiável e analítico.
O campo location é armazenado na origem como um JSON em formato de string. Na camada Silver, utilizamos a função FROM_JSON para converter esse campo em uma estrutura tipada (STRUCT), permitindo o acesso direto aos atributos de endereço e coordenadas geográficas, além da aplicação de regras de qualidade sobre esses dados.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze )
Níveis de Rigor das Expectations:
EXPECT: Apenas gera métricas. Ideal para entender a "sujeira" do dado sem interromper o fluxo.
DROP ROW: Garante que a camada Silver contenha apenas dados de confiança.
FAIL UPDATE: Bloqueia o processamento. Essencial para garantir que cálculos de impostos ou pagamentos nunca sejam feitos com dados nulos.
As Expectations também geram métricas automáticas no pipeline, permitindo monitorar a qualidade dos dados ao longo do tempo.
Camada Gold
A camada Gold é otimizada para o consumo final, fornecendo tabelas estáveis, simples e performáticas para analytics, BI e aplicações downstream.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM
Manutenção Autônoma (Vacuum e Optimize):
Diferente de tabelas Spark comuns, o DLT gerencia automaticamente o OPTIMIZE (compactação de arquivos pequenos) e o VACUUM (limpeza de arquivos antigos). Isso garante que, mesmo com múltiplas atualizações incrementais ao longo do tempo, as consultas na camada Gold permaneçam em alta performance.
Passo 3: Configurar o Pipeline no Unity Catalog
Agora que o código está pronto, precisamos criar o objeto de Pipeline para executá-lo.
Na barra lateral, clique em Jobs & Pipelines.
No menu "Create New", selecione a opção ETL pipeline (Build ETL pipelines using SQL and Python).
Na tela de configuração, você deve fornecer um catálogo e um esquema (Provide a catalog and schema) no canto superior esquerdo para que suas tabelas e logs sejam vinculados ao Unity Catalog.
Selecione Add existing assets para vincular o notebook criado no Passo 2.
Nota sobre Modernização: Ao selecionar seu código, o Databricks pode exibir um aviso de "Legacy configuration". Isso ocorre porque o Lakeflow prioriza o uso de arquivos de código bruto (.sql) para facilitar práticas de DevOps. Para este tutorial, seguiremos com o formato de Notebook devido à facilidade de visualização imediata dos dados, mas em ambientes produtivos de larga escala, a recomendação é a transição para Workspace Files.
Passo 4: Executar e Validar
Na tela do seu Pipeline, clique em Run pipeline.
O Databricks irá inicializar um cluster e você verá o gráfico de linhagem (DAG) aparecer na tela.
Acompanhe o processamento: o gráfico mostrará quantas linhas passaram da camada Bronze para a Gold.
Se alguma linha violar a regra theater_id IS NOT NULL definida na camada Silver, o DLT irá descartar a linha e registrar a métrica no painel de qualidade.
Conclusão
Você implementou com sucesso um pipeline de dados robusto utilizando a Arquitetura Medallion e o Delta Live Tables dentro do ecossistema Databricks Lakeflow. Ao seguir este guia, você estabeleceu uma base sólida para engenharia de dados moderna, garantindo:
Ingestão Inteligente: Compreensão da flexibilidade entre o processamento via Auto Loader para arquivos brutos e a ingestão de tabelas Delta existentes.
Governança Ativa: Implementação de Expectations para garantir que apenas dados de alta qualidade cheguem às camadas de consumo, reduzindo o tempo de depuração.
Performance Nativa: Uma arquitetura que se beneficia de manutenções automáticas como Optimize e Vacuum, garantindo consultas rápidas na camada Gold sem intervenção manual.
Linhagem e Transparência: Através do Unity Catalog, seu pipeline agora possui linhagem de dados automática, facilitando auditorias e conformidade.
Ao integrar uma ferramenta de ingestão como a Erathos com o Delta Live Tables, conseguimos separar claramente as responsabilidades entre ingestão e transformação, resultando em pipelines mais simples, governáveis e escaláveis.
Criando seu primeiro Pipeline de Dados com Medallion Architecture e Delta Live Tables (DLT)
Aprenda a construir um pipeline de dados robusto utilizando DLT, a arquitetura Medallion e governança via Unity Catalog no Databricks.
O Delta Live Tables (DLT) é o framework declarativo do Databricks para construção de pipelines de dados confiáveis, escaláveis e observáveis. Diferente de abordagens tradicionais baseadas em notebooks agendados ou scripts SQL isolados, o DLT foi projetado para resolver um problema comum em ambientes analíticos: a complexidade operacional de manter pipelines de dados consistentes ao longo do tempo.
Em projetos de engenharia de dados, é comum começar com transformações simples utilizando tabelas Delta e jobs do Databricks. No entanto, à medida que o volume de dados cresce e os pipelines se tornam mais críticos, surgem desafios como controle de dependências, tratamento de falhas, validação de qualidade dos dados, versionamento de schemas e observabilidade do fluxo ponta a ponta.
É nesse contexto que o DLT se torna a escolha mais adequada. Ao adotar uma abordagem declarativa, o engenheiro de dados descreve o estado desejado dos dados por exemplo, quais tabelas devem existir, suas regras de qualidade e suas dependências, enquanto o Databricks se encarrega automaticamente da orquestração, do gerenciamento de infraestrutura, do monitoramento e da recuperação em caso de falhas.
Recentemente integrado ao Databricks Lakeflow como parte dos Declarative Pipelines, o DLT se posiciona como a solução ideal para pipelines contínuos ou recorrentes que exigem confiabilidade, governança e facilidade de manutenção. Ele não substitui completamente outras formas de criação de tabelas no Databricks, mas se destaca em cenários onde a previsibilidade, a qualidade dos dados e a observabilidade são requisitos essenciais.
Neste artigo, exploramos como utilizar o Delta Live Tables para construir pipelines de dados bem estruturados, demonstrando na prática como ele pode ser integrado a processos de ingestão externos e utilizado como camada central de transformação dentro do Databricks.
Unity Catalog e Governança Unificada
Diferente de arquiteturas legadas que dependiam do DBFS, os pipelines modernos operam sob o Unity Catalog (UC). O UC oferece:
Governança Unificada: Controle de acesso centralizado e linhagem de dados automática.
Volumes vs. Tabelas: O Unity Catalog diferencia arquivos brutos (Volumes) de dados processados registrados como tabelas gerenciadas.
Isolamento: Facilidade em separar ambientes de
dev,stagingeproddentro do mesmo metastore.
O que é a Arquitetura Medallion?
A arquitetura Medallion descreve uma série de camadas de dados que denotam a qualidade dos dados armazenados no Lakehouse:
Bronze: A camada de pouso (landing zone). Os dados são mantidos em seu formato original, permitindo o reprocessamento se necessário.
Silver: Os dados são limpos, normalizados e validados. Aqui, aplicamos as Expectations (regras de qualidade).
Gold: Camada final, com dados agregados e prontos para o consumo por analistas de BI e modelos de Machine Learning.
Ao usar o DLT dentro do ecossistema Lakeflow, você ganha observabilidade nativa: o Databricks gera automaticamente o gráfico de linhagem (lineage) e monitora a saúde do pipeline sem que você precise configurar ferramentas externas.
Por que usar Delta Live Tables?
Gerenciamento de Infraestrutura: O Databricks escala automaticamente os recursos computacionais.
Qualidade de Dados Nativa: Defina expectativas (Expectations) para impedir que dados corrompidos cheguem às camadas finais.
Linhagem Automática: Visualize como os dados fluem da origem até o consumo final.
Suporte a Streaming e Batch: Processe dados em tempo real ou em lotes usando a mesma sintaxe SQL ou Python.
Para este guia, utilizaremos SQL, que é a linguagem mais comum para transformações analíticas no Databricks, mas o DLT também suporta Python integralmente.
Conhecimento Assumido
Para tirar o máximo proveito deste tutorial, certifique-se de compreender:
Conceitos básicos de SQL.
O conceito de Arquitetura Medallion.
Navegação básica no Workspace do Databricks.
Pré-requisitos: Preparando a Fonte de Dados (MongoDB)
Antes de iniciar o pipeline de dados no Databricks, precisamos de uma fonte de dados operacional. Neste tutorial, utilizaremos o MongoDB Atlas Free Tier como banco de dados de origem, simulando um cenário real de dados transacionais.
Criando um Cluster MongoDB Free Tier
Para criar um cluster gratuito no MongoDB, siga o tutorial oficial da MongoDB:
Deploy de um cluster Free Tier:
https://www.mongodb.com/pt-br/docs/atlas/tutorial/deploy-free-tier-cluster/
Guia de primeiros passos:
Após a criação do cluster, certifique-se de:
Criar um usuário de banco de dados
Liberar o IP de acesso (ou permitir acesso de qualquer IP para fins de teste)
Copiar a string de conexão
Passo 1: Preparar os Dados de Origem
Neste guia, os dados de origem não são acessados diretamente pela Databricks via conectores nativos ou Auto Loader. Em vez disso, utilizamos a Erathos como camada de ingestão, simulando um cenário real de arquitetura moderna onde a ingestão e transformação são responsabilidades bem definidas.
A Erathos é uma ferramenta de ingestão de dados que permite conectar diferentes fontes (bancos de dados, APIs e sistemas externos) e entregar esses dados diretamente no Lakehouse, abstraindo a complexidade de:
Autenticação
Extração incremental
Agendamento
Monitoramento
Escrita em Delta Lake
Conectando o MongoDB à Erathos
A Erathos possui um conector nativo para MongoDB Atlas.
Documentação do conector MongoDB:
Criação e gerenciamento de conexões:
Neste passo, você irá:
Criar uma conexão com o MongoDB Atlas utilizando a string de conexão
Selecionar a collection desejada
Definir o modo de sincronização (full ou incremental)
Configurando o Databricks como Destino
Após configurar a fonte, definimos o Databricks como destino dos dados.
A Erathos oferece integração direta com Databricks + Unity Catalog, garantindo que os dados já cheguem governados ao Lakehouse.
Documentação oficial:
Neste passo, você irá:
Informar o workspace Databricks
Selecionar o catálogo e o schema de destino
Persistir os dados como tabelas Delta
Resultado da Ingestão
Para este tutorial, a Erathos foi utilizada para:
Conectar-se a um banco de dados MongoDB (demo)
Ingerir a collection:
theaters(1.564 registros)
Persistir os dados como tabelas Delta no Databricks, dentro de um schema governado pelo Unity Catalog
A partir desse ponto, todo o processamento e transformação dos dados será realizado exclusivamente via Delta Live Tables, mantendo o foco deste artigo na camada de transformação e qualidade dos dados.
Governança e Organização dos Dados
Antes de iniciar o pipeline DLT, é fundamental garantir que o Schema de destino já exista no Unity Catalog. O DLT segue estritamente a hierarquia:
Catalog > Schema > Table
Sem um schema previamente criado, o pipeline não conseguirá registrar corretamente os metadados nem expor as tabelas para consumo externo.
Nota: Em um cenário real, a Erathos poderia estar ingerindo dados a partir de bancos transacionais, APIs ou sistemas de terceiros, entregando-os diretamente em um catálogo governado no Databricks.
Estratégias de Ingestão: Batch vs. Streaming
Antes de codificarmos nossa primeira camada, é importante entender como o DLT consome diferentes tipos de fontes. Independentemente de os dados terem sido ingeridos via Erathos, Auto Loader ou outro mecanismo, o DLT oferece suporte tanto a processamento em batch quanto streaming.
Auto Loader: Utilizado para ingerir arquivos brutos de forma incremental usando
cloud_files. Esta é a forma mais comum. Você aponta para uma pasta no Cloud Storage (S3, ADLS, GCS) ou um Unity Catalog Volume.Como funciona: O Databricks monitora a chegada de novos arquivos (JSON, CSV, Parquet) e processa apenas os novos.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json")
Via Delta Table (Stream from Table): Se a sua origem já for uma Tabela Delta (e não apenas arquivos soltos), ela precisa suportar o histórico de mudanças (Change Data Feed).
Como funciona: Você lê a tabela como um fluxo contínuo.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table)
Nota de Implementação: Neste guia, os dados de
theatersforam ingeridos previamente via Erathos e persistidas como tabelas Delta estáticas. Por esse motivo, utilizaremos o comandoLIVE TABLE(batch). Ainda assim, a arquitetura Medallion permanece a mesma, podendo ser facilmente adaptada para fontes incrementais ou streaming.
Pré-requisitos Técnicos no Databricks
Workspace Databricks com Unity Catalog habilitado.
Permissões para criar pipelines DLT e escrever em um esquema no seu catálogo.
Passo 2: Criar o Notebook de Transformação
1. No seu Workspace, clique em New > Notebook. 2. Dê o nome de dlt_medallion_pipeline. 3. Certifique-se de que a linguagem padrão seja SQL.
As definições de tabelas no Delta Live Tables são declarativas e residem em notebooks SQL ou Python. Cada comando CREATE OR REFRESH LIVE TABLE descreve o que a tabela deve ser, enquanto o Databricks gerencia automaticamente como os dados são processados, versionados e otimizados dentro do pipeline.
Camada Bronze
A camada Bronze representa o ponto de entrada dos dados no nosso Lakehouse. Neste cenário, os dados já foram ingeridos no Databricks através da Erathos, que é responsável pela extração e sincronização incremental da fonte de dados.
O objetivo principal da Bronze é a fidelidade: capturamos os dados com o mínimo de transformações possíveis, preservando o formato original, incluindo campos JSON para garantir rastreabilidade e permitir reprocessamentos futuros.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM
Camada Silver
A camada Silver é onde a densidade técnica aumenta. Aqui realizamos a estruturação dos dados, a aplicação de regras de qualidade e a normalização de campos complexos, como JSONs, transformando dados brutos em um formato confiável e analítico.
O campo location é armazenado na origem como um JSON em formato de string. Na camada Silver, utilizamos a função FROM_JSON para converter esse campo em uma estrutura tipada (STRUCT), permitindo o acesso direto aos atributos de endereço e coordenadas geográficas, além da aplicação de regras de qualidade sobre esses dados.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze )
Níveis de Rigor das Expectations:
EXPECT: Apenas gera métricas. Ideal para entender a "sujeira" do dado sem interromper o fluxo.
DROP ROW: Garante que a camada Silver contenha apenas dados de confiança.
FAIL UPDATE: Bloqueia o processamento. Essencial para garantir que cálculos de impostos ou pagamentos nunca sejam feitos com dados nulos.
As Expectations também geram métricas automáticas no pipeline, permitindo monitorar a qualidade dos dados ao longo do tempo.
Camada Gold
A camada Gold é otimizada para o consumo final, fornecendo tabelas estáveis, simples e performáticas para analytics, BI e aplicações downstream.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM
Manutenção Autônoma (Vacuum e Optimize):
Diferente de tabelas Spark comuns, o DLT gerencia automaticamente o OPTIMIZE (compactação de arquivos pequenos) e o VACUUM (limpeza de arquivos antigos). Isso garante que, mesmo com múltiplas atualizações incrementais ao longo do tempo, as consultas na camada Gold permaneçam em alta performance.
Passo 3: Configurar o Pipeline no Unity Catalog
Agora que o código está pronto, precisamos criar o objeto de Pipeline para executá-lo.
Na barra lateral, clique em Jobs & Pipelines.
No menu "Create New", selecione a opção ETL pipeline (Build ETL pipelines using SQL and Python).
Na tela de configuração, você deve fornecer um catálogo e um esquema (Provide a catalog and schema) no canto superior esquerdo para que suas tabelas e logs sejam vinculados ao Unity Catalog.
Selecione Add existing assets para vincular o notebook criado no Passo 2.
Nota sobre Modernização: Ao selecionar seu código, o Databricks pode exibir um aviso de "Legacy configuration". Isso ocorre porque o Lakeflow prioriza o uso de arquivos de código bruto (.sql) para facilitar práticas de DevOps. Para este tutorial, seguiremos com o formato de Notebook devido à facilidade de visualização imediata dos dados, mas em ambientes produtivos de larga escala, a recomendação é a transição para Workspace Files.
Passo 4: Executar e Validar
Na tela do seu Pipeline, clique em Run pipeline.
O Databricks irá inicializar um cluster e você verá o gráfico de linhagem (DAG) aparecer na tela.
Acompanhe o processamento: o gráfico mostrará quantas linhas passaram da camada Bronze para a Gold.
Se alguma linha violar a regra theater_id IS NOT NULL definida na camada Silver, o DLT irá descartar a linha e registrar a métrica no painel de qualidade.
Conclusão
Você implementou com sucesso um pipeline de dados robusto utilizando a Arquitetura Medallion e o Delta Live Tables dentro do ecossistema Databricks Lakeflow. Ao seguir este guia, você estabeleceu uma base sólida para engenharia de dados moderna, garantindo:
Ingestão Inteligente: Compreensão da flexibilidade entre o processamento via Auto Loader para arquivos brutos e a ingestão de tabelas Delta existentes.
Governança Ativa: Implementação de Expectations para garantir que apenas dados de alta qualidade cheguem às camadas de consumo, reduzindo o tempo de depuração.
Performance Nativa: Uma arquitetura que se beneficia de manutenções automáticas como Optimize e Vacuum, garantindo consultas rápidas na camada Gold sem intervenção manual.
Linhagem e Transparência: Através do Unity Catalog, seu pipeline agora possui linhagem de dados automática, facilitando auditorias e conformidade.
Ao integrar uma ferramenta de ingestão como a Erathos com o Delta Live Tables, conseguimos separar claramente as responsabilidades entre ingestão e transformação, resultando em pipelines mais simples, governáveis e escaláveis.
Criando seu primeiro Pipeline de Dados com Medallion Architecture e Delta Live Tables (DLT)
Aprenda a construir um pipeline de dados robusto utilizando DLT, a arquitetura Medallion e governança via Unity Catalog no Databricks.
O Delta Live Tables (DLT) é o framework declarativo do Databricks para construção de pipelines de dados confiáveis, escaláveis e observáveis. Diferente de abordagens tradicionais baseadas em notebooks agendados ou scripts SQL isolados, o DLT foi projetado para resolver um problema comum em ambientes analíticos: a complexidade operacional de manter pipelines de dados consistentes ao longo do tempo.
Em projetos de engenharia de dados, é comum começar com transformações simples utilizando tabelas Delta e jobs do Databricks. No entanto, à medida que o volume de dados cresce e os pipelines se tornam mais críticos, surgem desafios como controle de dependências, tratamento de falhas, validação de qualidade dos dados, versionamento de schemas e observabilidade do fluxo ponta a ponta.
É nesse contexto que o DLT se torna a escolha mais adequada. Ao adotar uma abordagem declarativa, o engenheiro de dados descreve o estado desejado dos dados por exemplo, quais tabelas devem existir, suas regras de qualidade e suas dependências, enquanto o Databricks se encarrega automaticamente da orquestração, do gerenciamento de infraestrutura, do monitoramento e da recuperação em caso de falhas.
Recentemente integrado ao Databricks Lakeflow como parte dos Declarative Pipelines, o DLT se posiciona como a solução ideal para pipelines contínuos ou recorrentes que exigem confiabilidade, governança e facilidade de manutenção. Ele não substitui completamente outras formas de criação de tabelas no Databricks, mas se destaca em cenários onde a previsibilidade, a qualidade dos dados e a observabilidade são requisitos essenciais.
Neste artigo, exploramos como utilizar o Delta Live Tables para construir pipelines de dados bem estruturados, demonstrando na prática como ele pode ser integrado a processos de ingestão externos e utilizado como camada central de transformação dentro do Databricks.
Unity Catalog e Governança Unificada
Diferente de arquiteturas legadas que dependiam do DBFS, os pipelines modernos operam sob o Unity Catalog (UC). O UC oferece:
Governança Unificada: Controle de acesso centralizado e linhagem de dados automática.
Volumes vs. Tabelas: O Unity Catalog diferencia arquivos brutos (Volumes) de dados processados registrados como tabelas gerenciadas.
Isolamento: Facilidade em separar ambientes de
dev,stagingeproddentro do mesmo metastore.
O que é a Arquitetura Medallion?
A arquitetura Medallion descreve uma série de camadas de dados que denotam a qualidade dos dados armazenados no Lakehouse:
Bronze: A camada de pouso (landing zone). Os dados são mantidos em seu formato original, permitindo o reprocessamento se necessário.
Silver: Os dados são limpos, normalizados e validados. Aqui, aplicamos as Expectations (regras de qualidade).
Gold: Camada final, com dados agregados e prontos para o consumo por analistas de BI e modelos de Machine Learning.
Ao usar o DLT dentro do ecossistema Lakeflow, você ganha observabilidade nativa: o Databricks gera automaticamente o gráfico de linhagem (lineage) e monitora a saúde do pipeline sem que você precise configurar ferramentas externas.
Por que usar Delta Live Tables?
Gerenciamento de Infraestrutura: O Databricks escala automaticamente os recursos computacionais.
Qualidade de Dados Nativa: Defina expectativas (Expectations) para impedir que dados corrompidos cheguem às camadas finais.
Linhagem Automática: Visualize como os dados fluem da origem até o consumo final.
Suporte a Streaming e Batch: Processe dados em tempo real ou em lotes usando a mesma sintaxe SQL ou Python.
Para este guia, utilizaremos SQL, que é a linguagem mais comum para transformações analíticas no Databricks, mas o DLT também suporta Python integralmente.
Conhecimento Assumido
Para tirar o máximo proveito deste tutorial, certifique-se de compreender:
Conceitos básicos de SQL.
O conceito de Arquitetura Medallion.
Navegação básica no Workspace do Databricks.
Pré-requisitos: Preparando a Fonte de Dados (MongoDB)
Antes de iniciar o pipeline de dados no Databricks, precisamos de uma fonte de dados operacional. Neste tutorial, utilizaremos o MongoDB Atlas Free Tier como banco de dados de origem, simulando um cenário real de dados transacionais.
Criando um Cluster MongoDB Free Tier
Para criar um cluster gratuito no MongoDB, siga o tutorial oficial da MongoDB:
Deploy de um cluster Free Tier:
https://www.mongodb.com/pt-br/docs/atlas/tutorial/deploy-free-tier-cluster/
Guia de primeiros passos:
Após a criação do cluster, certifique-se de:
Criar um usuário de banco de dados
Liberar o IP de acesso (ou permitir acesso de qualquer IP para fins de teste)
Copiar a string de conexão
Passo 1: Preparar os Dados de Origem
Neste guia, os dados de origem não são acessados diretamente pela Databricks via conectores nativos ou Auto Loader. Em vez disso, utilizamos a Erathos como camada de ingestão, simulando um cenário real de arquitetura moderna onde a ingestão e transformação são responsabilidades bem definidas.
A Erathos é uma ferramenta de ingestão de dados que permite conectar diferentes fontes (bancos de dados, APIs e sistemas externos) e entregar esses dados diretamente no Lakehouse, abstraindo a complexidade de:
Autenticação
Extração incremental
Agendamento
Monitoramento
Escrita em Delta Lake
Conectando o MongoDB à Erathos
A Erathos possui um conector nativo para MongoDB Atlas.
Documentação do conector MongoDB:
Criação e gerenciamento de conexões:
Neste passo, você irá:
Criar uma conexão com o MongoDB Atlas utilizando a string de conexão
Selecionar a collection desejada
Definir o modo de sincronização (full ou incremental)
Configurando o Databricks como Destino
Após configurar a fonte, definimos o Databricks como destino dos dados.
A Erathos oferece integração direta com Databricks + Unity Catalog, garantindo que os dados já cheguem governados ao Lakehouse.
Documentação oficial:
Neste passo, você irá:
Informar o workspace Databricks
Selecionar o catálogo e o schema de destino
Persistir os dados como tabelas Delta
Resultado da Ingestão
Para este tutorial, a Erathos foi utilizada para:
Conectar-se a um banco de dados MongoDB (demo)
Ingerir a collection:
theaters(1.564 registros)
Persistir os dados como tabelas Delta no Databricks, dentro de um schema governado pelo Unity Catalog
A partir desse ponto, todo o processamento e transformação dos dados será realizado exclusivamente via Delta Live Tables, mantendo o foco deste artigo na camada de transformação e qualidade dos dados.
Governança e Organização dos Dados
Antes de iniciar o pipeline DLT, é fundamental garantir que o Schema de destino já exista no Unity Catalog. O DLT segue estritamente a hierarquia:
Catalog > Schema > Table
Sem um schema previamente criado, o pipeline não conseguirá registrar corretamente os metadados nem expor as tabelas para consumo externo.
Nota: Em um cenário real, a Erathos poderia estar ingerindo dados a partir de bancos transacionais, APIs ou sistemas de terceiros, entregando-os diretamente em um catálogo governado no Databricks.
Estratégias de Ingestão: Batch vs. Streaming
Antes de codificarmos nossa primeira camada, é importante entender como o DLT consome diferentes tipos de fontes. Independentemente de os dados terem sido ingeridos via Erathos, Auto Loader ou outro mecanismo, o DLT oferece suporte tanto a processamento em batch quanto streaming.
Auto Loader: Utilizado para ingerir arquivos brutos de forma incremental usando
cloud_files. Esta é a forma mais comum. Você aponta para uma pasta no Cloud Storage (S3, ADLS, GCS) ou um Unity Catalog Volume.Como funciona: O Databricks monitora a chegada de novos arquivos (JSON, CSV, Parquet) e processa apenas os novos.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json")
Via Delta Table (Stream from Table): Se a sua origem já for uma Tabela Delta (e não apenas arquivos soltos), ela precisa suportar o histórico de mudanças (Change Data Feed).
Como funciona: Você lê a tabela como um fluxo contínuo.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table)
Nota de Implementação: Neste guia, os dados de
theatersforam ingeridos previamente via Erathos e persistidas como tabelas Delta estáticas. Por esse motivo, utilizaremos o comandoLIVE TABLE(batch). Ainda assim, a arquitetura Medallion permanece a mesma, podendo ser facilmente adaptada para fontes incrementais ou streaming.
Pré-requisitos Técnicos no Databricks
Workspace Databricks com Unity Catalog habilitado.
Permissões para criar pipelines DLT e escrever em um esquema no seu catálogo.
Passo 2: Criar o Notebook de Transformação
1. No seu Workspace, clique em New > Notebook. 2. Dê o nome de dlt_medallion_pipeline. 3. Certifique-se de que a linguagem padrão seja SQL.
As definições de tabelas no Delta Live Tables são declarativas e residem em notebooks SQL ou Python. Cada comando CREATE OR REFRESH LIVE TABLE descreve o que a tabela deve ser, enquanto o Databricks gerencia automaticamente como os dados são processados, versionados e otimizados dentro do pipeline.
Camada Bronze
A camada Bronze representa o ponto de entrada dos dados no nosso Lakehouse. Neste cenário, os dados já foram ingeridos no Databricks através da Erathos, que é responsável pela extração e sincronização incremental da fonte de dados.
O objetivo principal da Bronze é a fidelidade: capturamos os dados com o mínimo de transformações possíveis, preservando o formato original, incluindo campos JSON para garantir rastreabilidade e permitir reprocessamentos futuros.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM
Camada Silver
A camada Silver é onde a densidade técnica aumenta. Aqui realizamos a estruturação dos dados, a aplicação de regras de qualidade e a normalização de campos complexos, como JSONs, transformando dados brutos em um formato confiável e analítico.
O campo location é armazenado na origem como um JSON em formato de string. Na camada Silver, utilizamos a função FROM_JSON para converter esse campo em uma estrutura tipada (STRUCT), permitindo o acesso direto aos atributos de endereço e coordenadas geográficas, além da aplicação de regras de qualidade sobre esses dados.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze )
Níveis de Rigor das Expectations:
EXPECT: Apenas gera métricas. Ideal para entender a "sujeira" do dado sem interromper o fluxo.
DROP ROW: Garante que a camada Silver contenha apenas dados de confiança.
FAIL UPDATE: Bloqueia o processamento. Essencial para garantir que cálculos de impostos ou pagamentos nunca sejam feitos com dados nulos.
As Expectations também geram métricas automáticas no pipeline, permitindo monitorar a qualidade dos dados ao longo do tempo.
Camada Gold
A camada Gold é otimizada para o consumo final, fornecendo tabelas estáveis, simples e performáticas para analytics, BI e aplicações downstream.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM
Manutenção Autônoma (Vacuum e Optimize):
Diferente de tabelas Spark comuns, o DLT gerencia automaticamente o OPTIMIZE (compactação de arquivos pequenos) e o VACUUM (limpeza de arquivos antigos). Isso garante que, mesmo com múltiplas atualizações incrementais ao longo do tempo, as consultas na camada Gold permaneçam em alta performance.
Passo 3: Configurar o Pipeline no Unity Catalog
Agora que o código está pronto, precisamos criar o objeto de Pipeline para executá-lo.
Na barra lateral, clique em Jobs & Pipelines.
No menu "Create New", selecione a opção ETL pipeline (Build ETL pipelines using SQL and Python).
Na tela de configuração, você deve fornecer um catálogo e um esquema (Provide a catalog and schema) no canto superior esquerdo para que suas tabelas e logs sejam vinculados ao Unity Catalog.
Selecione Add existing assets para vincular o notebook criado no Passo 2.
Nota sobre Modernização: Ao selecionar seu código, o Databricks pode exibir um aviso de "Legacy configuration". Isso ocorre porque o Lakeflow prioriza o uso de arquivos de código bruto (.sql) para facilitar práticas de DevOps. Para este tutorial, seguiremos com o formato de Notebook devido à facilidade de visualização imediata dos dados, mas em ambientes produtivos de larga escala, a recomendação é a transição para Workspace Files.
Passo 4: Executar e Validar
Na tela do seu Pipeline, clique em Run pipeline.
O Databricks irá inicializar um cluster e você verá o gráfico de linhagem (DAG) aparecer na tela.
Acompanhe o processamento: o gráfico mostrará quantas linhas passaram da camada Bronze para a Gold.
Se alguma linha violar a regra theater_id IS NOT NULL definida na camada Silver, o DLT irá descartar a linha e registrar a métrica no painel de qualidade.
Conclusão
Você implementou com sucesso um pipeline de dados robusto utilizando a Arquitetura Medallion e o Delta Live Tables dentro do ecossistema Databricks Lakeflow. Ao seguir este guia, você estabeleceu uma base sólida para engenharia de dados moderna, garantindo:
Ingestão Inteligente: Compreensão da flexibilidade entre o processamento via Auto Loader para arquivos brutos e a ingestão de tabelas Delta existentes.
Governança Ativa: Implementação de Expectations para garantir que apenas dados de alta qualidade cheguem às camadas de consumo, reduzindo o tempo de depuração.
Performance Nativa: Uma arquitetura que se beneficia de manutenções automáticas como Optimize e Vacuum, garantindo consultas rápidas na camada Gold sem intervenção manual.
Linhagem e Transparência: Através do Unity Catalog, seu pipeline agora possui linhagem de dados automática, facilitando auditorias e conformidade.
Ao integrar uma ferramenta de ingestão como a Erathos com o Delta Live Tables, conseguimos separar claramente as responsabilidades entre ingestão e transformação, resultando em pipelines mais simples, governáveis e escaláveis.
Criando seu primeiro Pipeline de Dados com Medallion Architecture e Delta Live Tables (DLT)
Aprenda a construir um pipeline de dados robusto utilizando DLT, a arquitetura Medallion e governança via Unity Catalog no Databricks.
O Delta Live Tables (DLT) é o framework declarativo do Databricks para construção de pipelines de dados confiáveis, escaláveis e observáveis. Diferente de abordagens tradicionais baseadas em notebooks agendados ou scripts SQL isolados, o DLT foi projetado para resolver um problema comum em ambientes analíticos: a complexidade operacional de manter pipelines de dados consistentes ao longo do tempo.
Em projetos de engenharia de dados, é comum começar com transformações simples utilizando tabelas Delta e jobs do Databricks. No entanto, à medida que o volume de dados cresce e os pipelines se tornam mais críticos, surgem desafios como controle de dependências, tratamento de falhas, validação de qualidade dos dados, versionamento de schemas e observabilidade do fluxo ponta a ponta.
É nesse contexto que o DLT se torna a escolha mais adequada. Ao adotar uma abordagem declarativa, o engenheiro de dados descreve o estado desejado dos dados por exemplo, quais tabelas devem existir, suas regras de qualidade e suas dependências, enquanto o Databricks se encarrega automaticamente da orquestração, do gerenciamento de infraestrutura, do monitoramento e da recuperação em caso de falhas.
Recentemente integrado ao Databricks Lakeflow como parte dos Declarative Pipelines, o DLT se posiciona como a solução ideal para pipelines contínuos ou recorrentes que exigem confiabilidade, governança e facilidade de manutenção. Ele não substitui completamente outras formas de criação de tabelas no Databricks, mas se destaca em cenários onde a previsibilidade, a qualidade dos dados e a observabilidade são requisitos essenciais.
Neste artigo, exploramos como utilizar o Delta Live Tables para construir pipelines de dados bem estruturados, demonstrando na prática como ele pode ser integrado a processos de ingestão externos e utilizado como camada central de transformação dentro do Databricks.
Unity Catalog e Governança Unificada
Diferente de arquiteturas legadas que dependiam do DBFS, os pipelines modernos operam sob o Unity Catalog (UC). O UC oferece:
Governança Unificada: Controle de acesso centralizado e linhagem de dados automática.
Volumes vs. Tabelas: O Unity Catalog diferencia arquivos brutos (Volumes) de dados processados registrados como tabelas gerenciadas.
Isolamento: Facilidade em separar ambientes de
dev,stagingeproddentro do mesmo metastore.
O que é a Arquitetura Medallion?
A arquitetura Medallion descreve uma série de camadas de dados que denotam a qualidade dos dados armazenados no Lakehouse:
Bronze: A camada de pouso (landing zone). Os dados são mantidos em seu formato original, permitindo o reprocessamento se necessário.
Silver: Os dados são limpos, normalizados e validados. Aqui, aplicamos as Expectations (regras de qualidade).
Gold: Camada final, com dados agregados e prontos para o consumo por analistas de BI e modelos de Machine Learning.
Ao usar o DLT dentro do ecossistema Lakeflow, você ganha observabilidade nativa: o Databricks gera automaticamente o gráfico de linhagem (lineage) e monitora a saúde do pipeline sem que você precise configurar ferramentas externas.
Por que usar Delta Live Tables?
Gerenciamento de Infraestrutura: O Databricks escala automaticamente os recursos computacionais.
Qualidade de Dados Nativa: Defina expectativas (Expectations) para impedir que dados corrompidos cheguem às camadas finais.
Linhagem Automática: Visualize como os dados fluem da origem até o consumo final.
Suporte a Streaming e Batch: Processe dados em tempo real ou em lotes usando a mesma sintaxe SQL ou Python.
Para este guia, utilizaremos SQL, que é a linguagem mais comum para transformações analíticas no Databricks, mas o DLT também suporta Python integralmente.
Conhecimento Assumido
Para tirar o máximo proveito deste tutorial, certifique-se de compreender:
Conceitos básicos de SQL.
O conceito de Arquitetura Medallion.
Navegação básica no Workspace do Databricks.
Pré-requisitos: Preparando a Fonte de Dados (MongoDB)
Antes de iniciar o pipeline de dados no Databricks, precisamos de uma fonte de dados operacional. Neste tutorial, utilizaremos o MongoDB Atlas Free Tier como banco de dados de origem, simulando um cenário real de dados transacionais.
Criando um Cluster MongoDB Free Tier
Para criar um cluster gratuito no MongoDB, siga o tutorial oficial da MongoDB:
Deploy de um cluster Free Tier:
https://www.mongodb.com/pt-br/docs/atlas/tutorial/deploy-free-tier-cluster/
Guia de primeiros passos:
Após a criação do cluster, certifique-se de:
Criar um usuário de banco de dados
Liberar o IP de acesso (ou permitir acesso de qualquer IP para fins de teste)
Copiar a string de conexão
Passo 1: Preparar os Dados de Origem
Neste guia, os dados de origem não são acessados diretamente pela Databricks via conectores nativos ou Auto Loader. Em vez disso, utilizamos a Erathos como camada de ingestão, simulando um cenário real de arquitetura moderna onde a ingestão e transformação são responsabilidades bem definidas.
A Erathos é uma ferramenta de ingestão de dados que permite conectar diferentes fontes (bancos de dados, APIs e sistemas externos) e entregar esses dados diretamente no Lakehouse, abstraindo a complexidade de:
Autenticação
Extração incremental
Agendamento
Monitoramento
Escrita em Delta Lake
Conectando o MongoDB à Erathos
A Erathos possui um conector nativo para MongoDB Atlas.
Documentação do conector MongoDB:
Criação e gerenciamento de conexões:
Neste passo, você irá:
Criar uma conexão com o MongoDB Atlas utilizando a string de conexão
Selecionar a collection desejada
Definir o modo de sincronização (full ou incremental)
Configurando o Databricks como Destino
Após configurar a fonte, definimos o Databricks como destino dos dados.
A Erathos oferece integração direta com Databricks + Unity Catalog, garantindo que os dados já cheguem governados ao Lakehouse.
Documentação oficial:
Neste passo, você irá:
Informar o workspace Databricks
Selecionar o catálogo e o schema de destino
Persistir os dados como tabelas Delta
Resultado da Ingestão
Para este tutorial, a Erathos foi utilizada para:
Conectar-se a um banco de dados MongoDB (demo)
Ingerir a collection:
theaters(1.564 registros)
Persistir os dados como tabelas Delta no Databricks, dentro de um schema governado pelo Unity Catalog
A partir desse ponto, todo o processamento e transformação dos dados será realizado exclusivamente via Delta Live Tables, mantendo o foco deste artigo na camada de transformação e qualidade dos dados.
Governança e Organização dos Dados
Antes de iniciar o pipeline DLT, é fundamental garantir que o Schema de destino já exista no Unity Catalog. O DLT segue estritamente a hierarquia:
Catalog > Schema > Table
Sem um schema previamente criado, o pipeline não conseguirá registrar corretamente os metadados nem expor as tabelas para consumo externo.
Nota: Em um cenário real, a Erathos poderia estar ingerindo dados a partir de bancos transacionais, APIs ou sistemas de terceiros, entregando-os diretamente em um catálogo governado no Databricks.
Estratégias de Ingestão: Batch vs. Streaming
Antes de codificarmos nossa primeira camada, é importante entender como o DLT consome diferentes tipos de fontes. Independentemente de os dados terem sido ingeridos via Erathos, Auto Loader ou outro mecanismo, o DLT oferece suporte tanto a processamento em batch quanto streaming.
Auto Loader: Utilizado para ingerir arquivos brutos de forma incremental usando
cloud_files. Esta é a forma mais comum. Você aponta para uma pasta no Cloud Storage (S3, ADLS, GCS) ou um Unity Catalog Volume.Como funciona: O Databricks monitora a chegada de novos arquivos (JSON, CSV, Parquet) e processa apenas os novos.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json")
Via Delta Table (Stream from Table): Se a sua origem já for uma Tabela Delta (e não apenas arquivos soltos), ela precisa suportar o histórico de mudanças (Change Data Feed).
Como funciona: Você lê a tabela como um fluxo contínuo.
Código Exemplo:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table)
Nota de Implementação: Neste guia, os dados de
theatersforam ingeridos previamente via Erathos e persistidas como tabelas Delta estáticas. Por esse motivo, utilizaremos o comandoLIVE TABLE(batch). Ainda assim, a arquitetura Medallion permanece a mesma, podendo ser facilmente adaptada para fontes incrementais ou streaming.
Pré-requisitos Técnicos no Databricks
Workspace Databricks com Unity Catalog habilitado.
Permissões para criar pipelines DLT e escrever em um esquema no seu catálogo.
Passo 2: Criar o Notebook de Transformação
1. No seu Workspace, clique em New > Notebook. 2. Dê o nome de dlt_medallion_pipeline. 3. Certifique-se de que a linguagem padrão seja SQL.
As definições de tabelas no Delta Live Tables são declarativas e residem em notebooks SQL ou Python. Cada comando CREATE OR REFRESH LIVE TABLE descreve o que a tabela deve ser, enquanto o Databricks gerencia automaticamente como os dados são processados, versionados e otimizados dentro do pipeline.
Camada Bronze
A camada Bronze representa o ponto de entrada dos dados no nosso Lakehouse. Neste cenário, os dados já foram ingeridos no Databricks através da Erathos, que é responsável pela extração e sincronização incremental da fonte de dados.
O objetivo principal da Bronze é a fidelidade: capturamos os dados com o mínimo de transformações possíveis, preservando o formato original, incluindo campos JSON para garantir rastreabilidade e permitir reprocessamentos futuros.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM
Camada Silver
A camada Silver é onde a densidade técnica aumenta. Aqui realizamos a estruturação dos dados, a aplicação de regras de qualidade e a normalização de campos complexos, como JSONs, transformando dados brutos em um formato confiável e analítico.
O campo location é armazenado na origem como um JSON em formato de string. Na camada Silver, utilizamos a função FROM_JSON para converter esse campo em uma estrutura tipada (STRUCT), permitindo o acesso direto aos atributos de endereço e coordenadas geográficas, além da aplicação de regras de qualidade sobre esses dados.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze )
Níveis de Rigor das Expectations:
EXPECT: Apenas gera métricas. Ideal para entender a "sujeira" do dado sem interromper o fluxo.
DROP ROW: Garante que a camada Silver contenha apenas dados de confiança.
FAIL UPDATE: Bloqueia o processamento. Essencial para garantir que cálculos de impostos ou pagamentos nunca sejam feitos com dados nulos.
As Expectations também geram métricas automáticas no pipeline, permitindo monitorar a qualidade dos dados ao longo do tempo.
Camada Gold
A camada Gold é otimizada para o consumo final, fornecendo tabelas estáveis, simples e performáticas para analytics, BI e aplicações downstream.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM
Manutenção Autônoma (Vacuum e Optimize):
Diferente de tabelas Spark comuns, o DLT gerencia automaticamente o OPTIMIZE (compactação de arquivos pequenos) e o VACUUM (limpeza de arquivos antigos). Isso garante que, mesmo com múltiplas atualizações incrementais ao longo do tempo, as consultas na camada Gold permaneçam em alta performance.
Passo 3: Configurar o Pipeline no Unity Catalog
Agora que o código está pronto, precisamos criar o objeto de Pipeline para executá-lo.
Na barra lateral, clique em Jobs & Pipelines.
No menu "Create New", selecione a opção ETL pipeline (Build ETL pipelines using SQL and Python).
Na tela de configuração, você deve fornecer um catálogo e um esquema (Provide a catalog and schema) no canto superior esquerdo para que suas tabelas e logs sejam vinculados ao Unity Catalog.
Selecione Add existing assets para vincular o notebook criado no Passo 2.
Nota sobre Modernização: Ao selecionar seu código, o Databricks pode exibir um aviso de "Legacy configuration". Isso ocorre porque o Lakeflow prioriza o uso de arquivos de código bruto (.sql) para facilitar práticas de DevOps. Para este tutorial, seguiremos com o formato de Notebook devido à facilidade de visualização imediata dos dados, mas em ambientes produtivos de larga escala, a recomendação é a transição para Workspace Files.
Passo 4: Executar e Validar
Na tela do seu Pipeline, clique em Run pipeline.
O Databricks irá inicializar um cluster e você verá o gráfico de linhagem (DAG) aparecer na tela.
Acompanhe o processamento: o gráfico mostrará quantas linhas passaram da camada Bronze para a Gold.
Se alguma linha violar a regra theater_id IS NOT NULL definida na camada Silver, o DLT irá descartar a linha e registrar a métrica no painel de qualidade.
Conclusão
Você implementou com sucesso um pipeline de dados robusto utilizando a Arquitetura Medallion e o Delta Live Tables dentro do ecossistema Databricks Lakeflow. Ao seguir este guia, você estabeleceu uma base sólida para engenharia de dados moderna, garantindo:
Ingestão Inteligente: Compreensão da flexibilidade entre o processamento via Auto Loader para arquivos brutos e a ingestão de tabelas Delta existentes.
Governança Ativa: Implementação de Expectations para garantir que apenas dados de alta qualidade cheguem às camadas de consumo, reduzindo o tempo de depuração.
Performance Nativa: Uma arquitetura que se beneficia de manutenções automáticas como Optimize e Vacuum, garantindo consultas rápidas na camada Gold sem intervenção manual.
Linhagem e Transparência: Através do Unity Catalog, seu pipeline agora possui linhagem de dados automática, facilitando auditorias e conformidade.
Ao integrar uma ferramenta de ingestão como a Erathos com o Delta Live Tables, conseguimos separar claramente as responsabilidades entre ingestão e transformação, resultando em pipelines mais simples, governáveis e escaláveis.