Como organizar seus dados para que as queries parem de te custar uma fortuna
Particionamento e clustering no BigQuery reduzem dados lidos por query — e o custo junto. Guia com SQL, materialized views e monitoramento de gasto.

Se você já abriu uma query no BigQuery e tomou um susto com o preview de custo antes mesmo de executar — ou recebeu aquela fatura no fim do mês muito maior do que o esperado — você sabe o preço de uma modelagem mal feita. Particionamento, clustering, views e materialized views não são apenas detalhes técnicos: são a diferença entre pipelines que custam centavos e pipelines que drenam o orçamento silenciosamente.
Neste guia, vamos explorar como cada uma dessas técnicas funciona, quando aplicar, e como combiná-las para construir um data warehouse que entrega performance real — sem explodir o cartão de crédito da empresa.
Particionamento: Dividindo para Conquistar
O particionamento é uma técnica de otimização que envolve a divisão física de uma tabela grande em segmentos menores e mais gerenciáveis, chamados partições. Essa divisão é baseada nos valores de uma ou mais colunas da tabela, geralmente colunas de data/hora ou identificadores inteiros [1].
Como Funciona?
Quando uma tabela é particionada, os dados são organizados em blocos de armazenamento separados, onde cada bloco corresponde a uma partição específica. Por exemplo, uma tabela de vendas pode ser particionada por data, com cada dia, mês ou ano armazenado em uma partição distinta. Quando uma consulta é executada com um filtro na coluna de partição, o sistema de banco de dados pode escanear apenas as partições relevantes, ignorando as demais. Esse processo, conhecido como pruning (poda), reduz significativamente a quantidade de dados a serem lidos, resultando em consultas mais rápidas e custos operacionais menores [1].
Benefícios do Particionamento
Melhora da Performance de Consultas: Ao reduzir o volume de dados a serem escaneados, as consultas que utilizam filtros nas colunas de partição são executadas muito mais rapidamente.
Redução de Custos: Muitos data warehouses baseados em nuvem, como o Google BigQuery, cobram com base na quantidade de dados processados. O particionamento minimiza essa quantidade, impactando diretamente nos custos [1].
Gerenciamento Simplificado: Facilita a manutenção da tabela, permitindo operações como exclusão ou expiração de dados em nível de partição, sem afetar o restante da tabela. Isso é particularmente útil para políticas de retenção de dados [1].
Estimativa de Custos de Consulta: Em sistemas como o BigQuery, o particionamento permite uma estimativa mais precisa dos custos de uma consulta antes de sua execução, pois o sistema pode determinar quais partições serão escaneadas [1].
Tipos Comuns de Particionamento
Os tipos de particionamento variam entre as plataformas, mas os mais comuns incluem:
Particionamento por Coluna de Tempo: Baseado em colunas
DATE,TIMESTAMPouDATETIME. Os dados são automaticamente alocados em partições horárias, diárias, mensais ou anuais. Exemplo:PARTITION BY DATE(timestamp_col).Particionamento por Tempo de Ingestão: O sistema atribui automaticamente os dados a partições com base no momento em que são ingeridos. Uma pseudocoluna (ex:
_PARTITIONTIMEno BigQuery) é usada para essa finalidade.Particionamento por Intervalo de Inteiros: Baseado em uma coluna
INTEGER, onde as partições são definidas por intervalos de valores. Exemplo:PARTITION BY RANGE_BUCKET(customer_id, GENERATE_ARRAY(0, 1000000, 10000)).
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data no BigQuery, você pode usar a seguinte sintaxe:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_particionada` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda OPTIONS( description="Tabela de vendas particionada por data" )
Para consultar dados de uma partição específica, a cláusula WHERE é utilizada para filtrar pela coluna de partição:
SELECT produto, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` WHERE data_venda = '2023-01-15' GROUP BY
Este exemplo demonstra como o particionamento permite que o BigQuery escaneie apenas a partição correspondente a '2023-01-15', otimizando a consulta. [1]
Clustering: Organizando os Dados para Acelerar Consultas
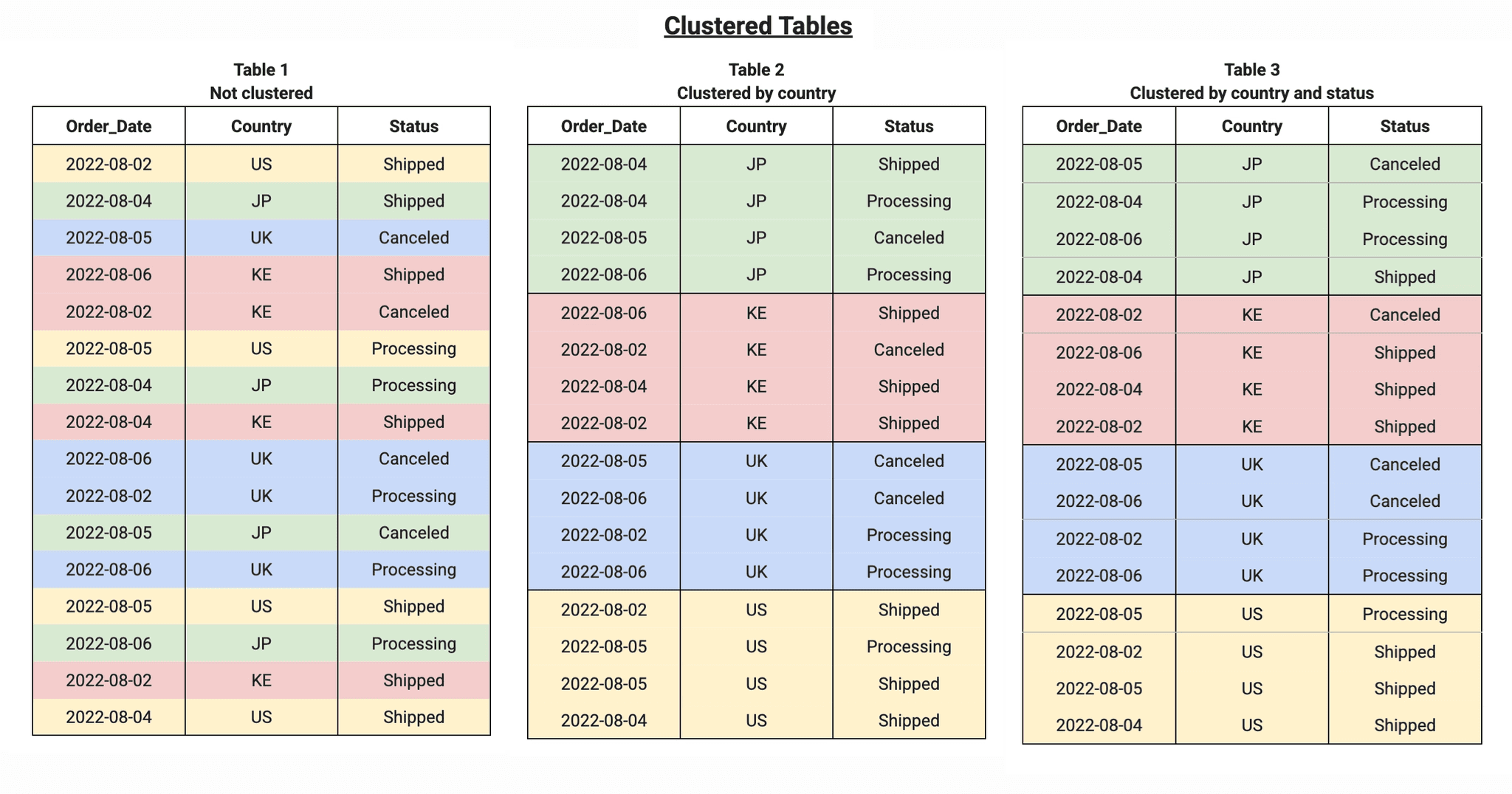
Enquanto o particionamento divide uma tabela em segmentos físicos, o clustering (ou agrupamento) organiza os dados dentro dessas partições (ou da tabela inteira, se não particionada) com base em colunas específicas definidas pelo usuário [2]. Pense no particionamento como a criação de gavetas em um armário, e no clustering como a organização dos itens dentro de cada gaveta em uma ordem lógica.
Como Funciona?
O clustering funciona ordenando os blocos de armazenamento de dados com base nos valores das colunas clusterizadas. Quando uma consulta filtra ou agrega dados por essas colunas, o sistema de banco de dados pode escanear apenas os blocos relevantes, em vez de toda a partição ou tabela. Isso é particularmente eficaz para colunas com alta cardinalidade (muitos valores distintos) [2].
Por exemplo, se uma tabela de transações for clusterizada pela coluna customer_id, todas as transações de um mesmo cliente serão armazenadas fisicamente próximas. Uma consulta que busca transações de um customer_id específico se beneficiará enormemente, pois o sistema precisará ler apenas uma pequena porção dos dados.
Benefícios do Clustering
Melhora da Performance em Filtros e Agregações: Acelera consultas que filtram ou agregam dados em colunas clusterizadas, especialmente aquelas com alta cardinalidade.
Redução de Dados Escaneados: Similar ao particionamento, o clustering permite que o sistema ignore blocos de dados irrelevantes, diminuindo a quantidade de dados processados e, consequentemente, os custos [2].
Otimização para Múltiplas Colunas: É possível clusterizar por múltiplas colunas, e a ordem dessas colunas é importante. O sistema otimiza a busca da esquerda para a direita, priorizando a primeira coluna clusterizada [2].
Quando Usar Clustering?
Granularidade Fina: Quando o particionamento não oferece a granularidade necessária para otimizar consultas específicas.
Filtros em Colunas de Alta Cardinalidade: Ideal para colunas com muitos valores distintos, onde o particionamento seria impraticável ou ineficiente.
Consultas com Múltiplos Filtros ou Agregações: Quando as consultas frequentemente utilizam filtros ou agregações em várias colunas [2].
Tabelas ou Partições Grandes: Tabelas ou partições com mais de 64 MB geralmente se beneficiam do clustering [2].
Combinando Particionamento e Clustering
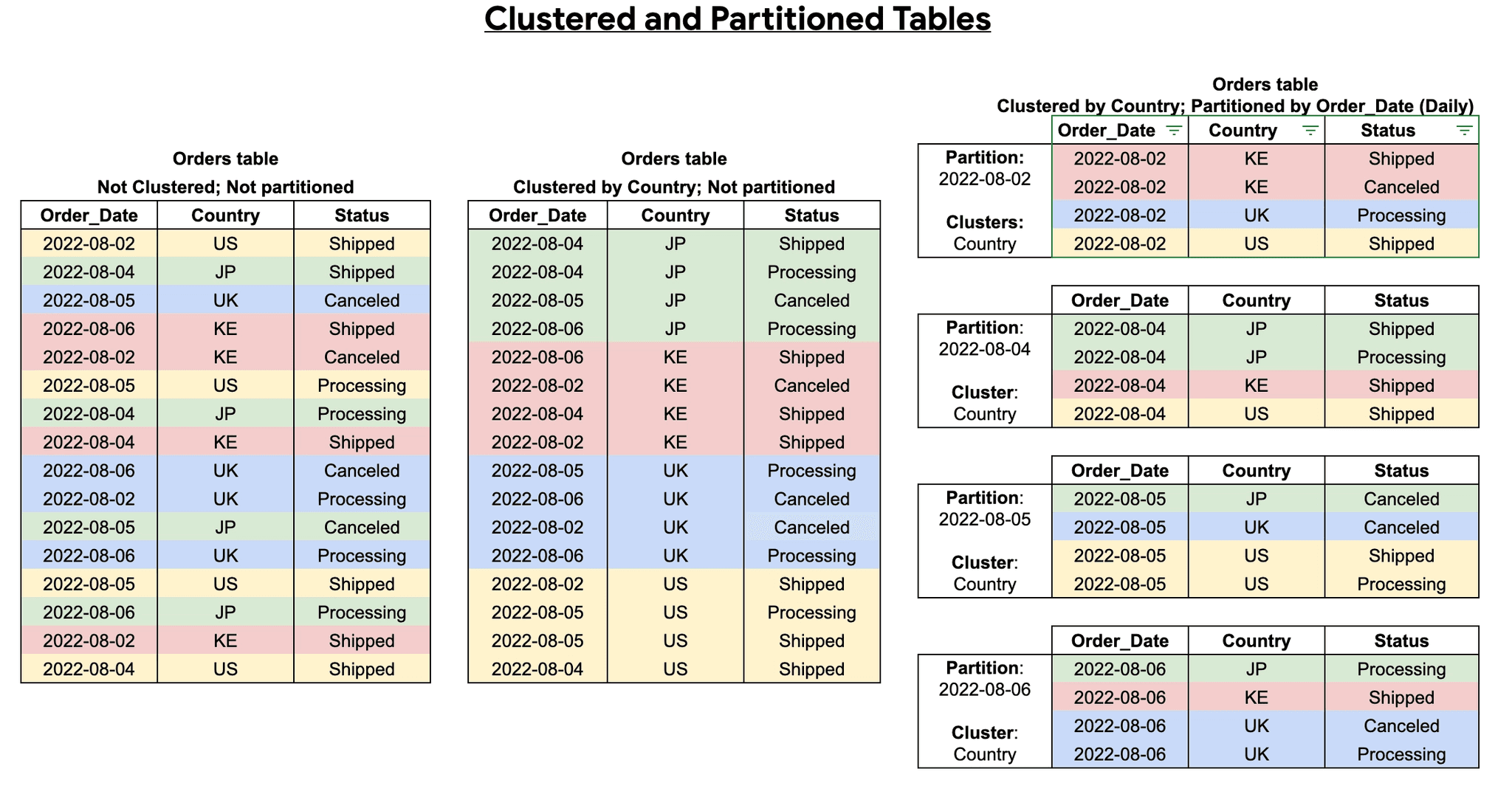
A combinação de particionamento e clustering é uma estratégia poderosa para otimização de desempenho. Primeiro, a tabela é dividida em partições (por exemplo, por data), e então, dentro de cada partição, os dados são clusterizados por uma ou mais colunas (por exemplo, customer_id ou product_category). Isso oferece uma otimização em duas camadas, resultando em um desempenho de consulta ainda melhor [2].
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data e clusterizada por produto e id no BigQuery:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_part_clustered` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda CLUSTER BY produto, id OPTIONS( description="Tabela de vendas particionada por data e clusterizada por produto e id" )
Neste exemplo, os dados são primeiro divididos por data_venda, e dentro de cada partição de data, são organizados por produto e, em seguida, por id. Uma consulta que filtra por data_venda e produto será altamente otimizada. [2]
Tabelas, Views e Materialized Views: Qual a Diferença?
Além de otimizar o armazenamento físico com particionamento e clustering, a modelagem de dados também envolve a escolha da estrutura lógica correta para expor e consumir esses dados. As três principais opções são Tabelas, Views (Visualizações) e Materialized Views (Visualizações Materializadas).
1. Tabelas (Tables)
As tabelas são a estrutura fundamental de armazenamento em qualquer banco de dados relacional ou data warehouse. Elas armazenam os dados fisicamente no disco.
Características: Os dados são persistidos fisicamente. Operações de DML (Insert, Update, Delete) modificam os dados diretamente na tabela.
Performance: A performance de leitura depende de como a tabela está estruturada (índices, particionamento, clustering).
Custo: Você paga pelo armazenamento físico dos dados e pelo processamento das consultas realizadas sobre eles.
Quando usar: Para armazenar os dados brutos ou processados que formam a base do seu data warehouse.
2. Views (Visualizações Lógicas)
Uma View é essencialmente uma consulta SQL salva que atua como uma tabela virtual. Ela não armazena dados fisicamente; em vez disso, a consulta subjacente é executada toda vez que a View é consultada [3].
Características: Não ocupam espaço de armazenamento (além da definição da query). Sempre retornam os dados mais atualizados da(s) tabela(s) base.
Performance: A performance depende inteiramente da complexidade da query subjacente e do volume de dados nas tabelas base no momento da execução. Consultas complexas em Views podem ser lentas.
Custo: Você paga apenas pelo processamento da consulta toda vez que a View é acessada.
Quando usar:
Para simplificar consultas complexas (encapsulando joins e agregações).
Para restringir o acesso a colunas ou linhas específicas de uma tabela base (segurança).
Para criar uma camada de abstração lógica sobre o modelo físico.
Exemplo de Criação de View:
CREATE VIEW `seu_projeto.seu_dataset.view_vendas_diarias` AS SELECT data_venda, SUM(valor) as total_vendas, COUNT(id) as qtd_transacoes FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY
3. Materialized Views (Visualizações Materializadas)
As Materialized Views combinam características de Tabelas e Views. Elas são definidas por uma consulta SQL (como uma View), mas o resultado dessa consulta é pré-computado e armazenado fisicamente no disco (como uma Tabela) [4].
Características: Armazenam dados fisicamente. Precisam ser "atualizadas" (refreshed) para refletir as mudanças nas tabelas base. A atualização pode ser manual, agendada ou automática (incremental), dependendo do banco de dados.
Performance: Oferecem performance de leitura extremamente rápida, pois os dados já estão pré-computados (especialmente útil para agregações pesadas).
Custo: Você paga pelo armazenamento dos dados pré-computados, pelo processamento necessário para atualizar a Materialized View e pelas consultas feitas a ela (que geralmente são muito mais baratas do que consultar as tabelas base).
Quando usar:
Para dashboards e relatórios que exigem tempos de resposta em milissegundos.
Quando uma mesma agregação complexa é consultada repetidamente por múltiplos usuários ou processos.
Quando a latência de dados (dados ligeiramente desatualizados entre os ciclos de atualização) é aceitável [4].
Exemplo de Criação de Materialized View (BigQuery):
CREATE MATERIALIZED VIEW `seu_projeto.seu_dataset.mv_vendas_mensais` AS SELECT EXTRACT(MONTH FROM data_venda) as mes, EXTRACT(YEAR FROM data_venda) as ano, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY mes,
Resumo Comparativo
Característica | Tabela | View | Materialized View |
|---|---|---|---|
Armazenamento | Físico | Lógico (Apenas a Query) | Físico (Pré-computado) |
Freshness dos Dados | Atualizado via DML | Sempre em tempo real | Depende da frequência de atualização (Refresh) |
Performance de Leitura | Alta (se otimizada) | Depende da query base | Muito Alta |
Custos Envolvidos | Armazenamento + Query | Apenas Query | Armazenamento + Refresh + Query (mais barata) |
Conclusão
A modelagem de dados moderna exige um entendimento profundo de como os dados são armazenados e acessados. O particionamento e o clustering são ferramentas indispensáveis para organizar fisicamente grandes volumes de dados, reduzindo custos e acelerando consultas através da minimização da leitura de dados desnecessários.
Por outro lado, a escolha entre Tabelas, Views e Materialized Views define a arquitetura lógica do seu data warehouse. Enquanto as Tabelas guardam a verdade absoluta, as Views oferecem flexibilidade e segurança, e as Materialized Views entregam a performance extrema necessária para análises em larga escala.
Dominar essas técnicas é metade do caminho. A outra metade é garantir que os dados chegam até essas estruturas de forma confiável — sem surpresas, sem black boxes, sem manutenção interminável. É exatamente isso que a Erathos resolve.
Referências
[1] Google Cloud. "Introduction to partitioned tables". Disponível em: https://cloud.google.com/bigquery/docs/partitioned-tables
[2] Google Cloud. "Introduction to clustered tables". Disponível em: https://cloud.google.com/bigquery/docs/clustered-tables
[3] Databricks. "Tables and views in Databricks". Disponível em: https://docs.databricks.com/aws/en/data-engineering/tables-views
[4] Snowflake. "Working with Materialized Views". Disponível em: https://docs.snowflake.com/en/user-guide/views-materialized
Se você já abriu uma query no BigQuery e tomou um susto com o preview de custo antes mesmo de executar — ou recebeu aquela fatura no fim do mês muito maior do que o esperado — você sabe o preço de uma modelagem mal feita. Particionamento, clustering, views e materialized views não são apenas detalhes técnicos: são a diferença entre pipelines que custam centavos e pipelines que drenam o orçamento silenciosamente.
Neste guia, vamos explorar como cada uma dessas técnicas funciona, quando aplicar, e como combiná-las para construir um data warehouse que entrega performance real — sem explodir o cartão de crédito da empresa.
Particionamento: Dividindo para Conquistar
O particionamento é uma técnica de otimização que envolve a divisão física de uma tabela grande em segmentos menores e mais gerenciáveis, chamados partições. Essa divisão é baseada nos valores de uma ou mais colunas da tabela, geralmente colunas de data/hora ou identificadores inteiros [1].
Como Funciona?
Quando uma tabela é particionada, os dados são organizados em blocos de armazenamento separados, onde cada bloco corresponde a uma partição específica. Por exemplo, uma tabela de vendas pode ser particionada por data, com cada dia, mês ou ano armazenado em uma partição distinta. Quando uma consulta é executada com um filtro na coluna de partição, o sistema de banco de dados pode escanear apenas as partições relevantes, ignorando as demais. Esse processo, conhecido como pruning (poda), reduz significativamente a quantidade de dados a serem lidos, resultando em consultas mais rápidas e custos operacionais menores [1].
Benefícios do Particionamento
Melhora da Performance de Consultas: Ao reduzir o volume de dados a serem escaneados, as consultas que utilizam filtros nas colunas de partição são executadas muito mais rapidamente.
Redução de Custos: Muitos data warehouses baseados em nuvem, como o Google BigQuery, cobram com base na quantidade de dados processados. O particionamento minimiza essa quantidade, impactando diretamente nos custos [1].
Gerenciamento Simplificado: Facilita a manutenção da tabela, permitindo operações como exclusão ou expiração de dados em nível de partição, sem afetar o restante da tabela. Isso é particularmente útil para políticas de retenção de dados [1].
Estimativa de Custos de Consulta: Em sistemas como o BigQuery, o particionamento permite uma estimativa mais precisa dos custos de uma consulta antes de sua execução, pois o sistema pode determinar quais partições serão escaneadas [1].
Tipos Comuns de Particionamento
Os tipos de particionamento variam entre as plataformas, mas os mais comuns incluem:
Particionamento por Coluna de Tempo: Baseado em colunas
DATE,TIMESTAMPouDATETIME. Os dados são automaticamente alocados em partições horárias, diárias, mensais ou anuais. Exemplo:PARTITION BY DATE(timestamp_col).Particionamento por Tempo de Ingestão: O sistema atribui automaticamente os dados a partições com base no momento em que são ingeridos. Uma pseudocoluna (ex:
_PARTITIONTIMEno BigQuery) é usada para essa finalidade.Particionamento por Intervalo de Inteiros: Baseado em uma coluna
INTEGER, onde as partições são definidas por intervalos de valores. Exemplo:PARTITION BY RANGE_BUCKET(customer_id, GENERATE_ARRAY(0, 1000000, 10000)).
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data no BigQuery, você pode usar a seguinte sintaxe:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_particionada` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda OPTIONS( description="Tabela de vendas particionada por data" )
Para consultar dados de uma partição específica, a cláusula WHERE é utilizada para filtrar pela coluna de partição:
SELECT produto, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` WHERE data_venda = '2023-01-15' GROUP BY
Este exemplo demonstra como o particionamento permite que o BigQuery escaneie apenas a partição correspondente a '2023-01-15', otimizando a consulta. [1]
Clustering: Organizando os Dados para Acelerar Consultas
Enquanto o particionamento divide uma tabela em segmentos físicos, o clustering (ou agrupamento) organiza os dados dentro dessas partições (ou da tabela inteira, se não particionada) com base em colunas específicas definidas pelo usuário [2]. Pense no particionamento como a criação de gavetas em um armário, e no clustering como a organização dos itens dentro de cada gaveta em uma ordem lógica.
Como Funciona?
O clustering funciona ordenando os blocos de armazenamento de dados com base nos valores das colunas clusterizadas. Quando uma consulta filtra ou agrega dados por essas colunas, o sistema de banco de dados pode escanear apenas os blocos relevantes, em vez de toda a partição ou tabela. Isso é particularmente eficaz para colunas com alta cardinalidade (muitos valores distintos) [2].
Por exemplo, se uma tabela de transações for clusterizada pela coluna customer_id, todas as transações de um mesmo cliente serão armazenadas fisicamente próximas. Uma consulta que busca transações de um customer_id específico se beneficiará enormemente, pois o sistema precisará ler apenas uma pequena porção dos dados.
Benefícios do Clustering
Melhora da Performance em Filtros e Agregações: Acelera consultas que filtram ou agregam dados em colunas clusterizadas, especialmente aquelas com alta cardinalidade.
Redução de Dados Escaneados: Similar ao particionamento, o clustering permite que o sistema ignore blocos de dados irrelevantes, diminuindo a quantidade de dados processados e, consequentemente, os custos [2].
Otimização para Múltiplas Colunas: É possível clusterizar por múltiplas colunas, e a ordem dessas colunas é importante. O sistema otimiza a busca da esquerda para a direita, priorizando a primeira coluna clusterizada [2].
Quando Usar Clustering?
Granularidade Fina: Quando o particionamento não oferece a granularidade necessária para otimizar consultas específicas.
Filtros em Colunas de Alta Cardinalidade: Ideal para colunas com muitos valores distintos, onde o particionamento seria impraticável ou ineficiente.
Consultas com Múltiplos Filtros ou Agregações: Quando as consultas frequentemente utilizam filtros ou agregações em várias colunas [2].
Tabelas ou Partições Grandes: Tabelas ou partições com mais de 64 MB geralmente se beneficiam do clustering [2].
Combinando Particionamento e Clustering
A combinação de particionamento e clustering é uma estratégia poderosa para otimização de desempenho. Primeiro, a tabela é dividida em partições (por exemplo, por data), e então, dentro de cada partição, os dados são clusterizados por uma ou mais colunas (por exemplo, customer_id ou product_category). Isso oferece uma otimização em duas camadas, resultando em um desempenho de consulta ainda melhor [2].
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data e clusterizada por produto e id no BigQuery:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_part_clustered` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda CLUSTER BY produto, id OPTIONS( description="Tabela de vendas particionada por data e clusterizada por produto e id" )
Neste exemplo, os dados são primeiro divididos por data_venda, e dentro de cada partição de data, são organizados por produto e, em seguida, por id. Uma consulta que filtra por data_venda e produto será altamente otimizada. [2]
Tabelas, Views e Materialized Views: Qual a Diferença?
Além de otimizar o armazenamento físico com particionamento e clustering, a modelagem de dados também envolve a escolha da estrutura lógica correta para expor e consumir esses dados. As três principais opções são Tabelas, Views (Visualizações) e Materialized Views (Visualizações Materializadas).
1. Tabelas (Tables)
As tabelas são a estrutura fundamental de armazenamento em qualquer banco de dados relacional ou data warehouse. Elas armazenam os dados fisicamente no disco.
Características: Os dados são persistidos fisicamente. Operações de DML (Insert, Update, Delete) modificam os dados diretamente na tabela.
Performance: A performance de leitura depende de como a tabela está estruturada (índices, particionamento, clustering).
Custo: Você paga pelo armazenamento físico dos dados e pelo processamento das consultas realizadas sobre eles.
Quando usar: Para armazenar os dados brutos ou processados que formam a base do seu data warehouse.
2. Views (Visualizações Lógicas)
Uma View é essencialmente uma consulta SQL salva que atua como uma tabela virtual. Ela não armazena dados fisicamente; em vez disso, a consulta subjacente é executada toda vez que a View é consultada [3].
Características: Não ocupam espaço de armazenamento (além da definição da query). Sempre retornam os dados mais atualizados da(s) tabela(s) base.
Performance: A performance depende inteiramente da complexidade da query subjacente e do volume de dados nas tabelas base no momento da execução. Consultas complexas em Views podem ser lentas.
Custo: Você paga apenas pelo processamento da consulta toda vez que a View é acessada.
Quando usar:
Para simplificar consultas complexas (encapsulando joins e agregações).
Para restringir o acesso a colunas ou linhas específicas de uma tabela base (segurança).
Para criar uma camada de abstração lógica sobre o modelo físico.
Exemplo de Criação de View:
CREATE VIEW `seu_projeto.seu_dataset.view_vendas_diarias` AS SELECT data_venda, SUM(valor) as total_vendas, COUNT(id) as qtd_transacoes FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY
3. Materialized Views (Visualizações Materializadas)
As Materialized Views combinam características de Tabelas e Views. Elas são definidas por uma consulta SQL (como uma View), mas o resultado dessa consulta é pré-computado e armazenado fisicamente no disco (como uma Tabela) [4].
Características: Armazenam dados fisicamente. Precisam ser "atualizadas" (refreshed) para refletir as mudanças nas tabelas base. A atualização pode ser manual, agendada ou automática (incremental), dependendo do banco de dados.
Performance: Oferecem performance de leitura extremamente rápida, pois os dados já estão pré-computados (especialmente útil para agregações pesadas).
Custo: Você paga pelo armazenamento dos dados pré-computados, pelo processamento necessário para atualizar a Materialized View e pelas consultas feitas a ela (que geralmente são muito mais baratas do que consultar as tabelas base).
Quando usar:
Para dashboards e relatórios que exigem tempos de resposta em milissegundos.
Quando uma mesma agregação complexa é consultada repetidamente por múltiplos usuários ou processos.
Quando a latência de dados (dados ligeiramente desatualizados entre os ciclos de atualização) é aceitável [4].
Exemplo de Criação de Materialized View (BigQuery):
CREATE MATERIALIZED VIEW `seu_projeto.seu_dataset.mv_vendas_mensais` AS SELECT EXTRACT(MONTH FROM data_venda) as mes, EXTRACT(YEAR FROM data_venda) as ano, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY mes,
Resumo Comparativo
Característica | Tabela | View | Materialized View |
|---|---|---|---|
Armazenamento | Físico | Lógico (Apenas a Query) | Físico (Pré-computado) |
Freshness dos Dados | Atualizado via DML | Sempre em tempo real | Depende da frequência de atualização (Refresh) |
Performance de Leitura | Alta (se otimizada) | Depende da query base | Muito Alta |
Custos Envolvidos | Armazenamento + Query | Apenas Query | Armazenamento + Refresh + Query (mais barata) |
Conclusão
A modelagem de dados moderna exige um entendimento profundo de como os dados são armazenados e acessados. O particionamento e o clustering são ferramentas indispensáveis para organizar fisicamente grandes volumes de dados, reduzindo custos e acelerando consultas através da minimização da leitura de dados desnecessários.
Por outro lado, a escolha entre Tabelas, Views e Materialized Views define a arquitetura lógica do seu data warehouse. Enquanto as Tabelas guardam a verdade absoluta, as Views oferecem flexibilidade e segurança, e as Materialized Views entregam a performance extrema necessária para análises em larga escala.
Dominar essas técnicas é metade do caminho. A outra metade é garantir que os dados chegam até essas estruturas de forma confiável — sem surpresas, sem black boxes, sem manutenção interminável. É exatamente isso que a Erathos resolve.
Referências
[1] Google Cloud. "Introduction to partitioned tables". Disponível em: https://cloud.google.com/bigquery/docs/partitioned-tables
[2] Google Cloud. "Introduction to clustered tables". Disponível em: https://cloud.google.com/bigquery/docs/clustered-tables
[3] Databricks. "Tables and views in Databricks". Disponível em: https://docs.databricks.com/aws/en/data-engineering/tables-views
[4] Snowflake. "Working with Materialized Views". Disponível em: https://docs.snowflake.com/en/user-guide/views-materialized
Se você já abriu uma query no BigQuery e tomou um susto com o preview de custo antes mesmo de executar — ou recebeu aquela fatura no fim do mês muito maior do que o esperado — você sabe o preço de uma modelagem mal feita. Particionamento, clustering, views e materialized views não são apenas detalhes técnicos: são a diferença entre pipelines que custam centavos e pipelines que drenam o orçamento silenciosamente.
Neste guia, vamos explorar como cada uma dessas técnicas funciona, quando aplicar, e como combiná-las para construir um data warehouse que entrega performance real — sem explodir o cartão de crédito da empresa.
Particionamento: Dividindo para Conquistar
O particionamento é uma técnica de otimização que envolve a divisão física de uma tabela grande em segmentos menores e mais gerenciáveis, chamados partições. Essa divisão é baseada nos valores de uma ou mais colunas da tabela, geralmente colunas de data/hora ou identificadores inteiros [1].
Como Funciona?
Quando uma tabela é particionada, os dados são organizados em blocos de armazenamento separados, onde cada bloco corresponde a uma partição específica. Por exemplo, uma tabela de vendas pode ser particionada por data, com cada dia, mês ou ano armazenado em uma partição distinta. Quando uma consulta é executada com um filtro na coluna de partição, o sistema de banco de dados pode escanear apenas as partições relevantes, ignorando as demais. Esse processo, conhecido como pruning (poda), reduz significativamente a quantidade de dados a serem lidos, resultando em consultas mais rápidas e custos operacionais menores [1].
Benefícios do Particionamento
Melhora da Performance de Consultas: Ao reduzir o volume de dados a serem escaneados, as consultas que utilizam filtros nas colunas de partição são executadas muito mais rapidamente.
Redução de Custos: Muitos data warehouses baseados em nuvem, como o Google BigQuery, cobram com base na quantidade de dados processados. O particionamento minimiza essa quantidade, impactando diretamente nos custos [1].
Gerenciamento Simplificado: Facilita a manutenção da tabela, permitindo operações como exclusão ou expiração de dados em nível de partição, sem afetar o restante da tabela. Isso é particularmente útil para políticas de retenção de dados [1].
Estimativa de Custos de Consulta: Em sistemas como o BigQuery, o particionamento permite uma estimativa mais precisa dos custos de uma consulta antes de sua execução, pois o sistema pode determinar quais partições serão escaneadas [1].
Tipos Comuns de Particionamento
Os tipos de particionamento variam entre as plataformas, mas os mais comuns incluem:
Particionamento por Coluna de Tempo: Baseado em colunas
DATE,TIMESTAMPouDATETIME. Os dados são automaticamente alocados em partições horárias, diárias, mensais ou anuais. Exemplo:PARTITION BY DATE(timestamp_col).Particionamento por Tempo de Ingestão: O sistema atribui automaticamente os dados a partições com base no momento em que são ingeridos. Uma pseudocoluna (ex:
_PARTITIONTIMEno BigQuery) é usada para essa finalidade.Particionamento por Intervalo de Inteiros: Baseado em uma coluna
INTEGER, onde as partições são definidas por intervalos de valores. Exemplo:PARTITION BY RANGE_BUCKET(customer_id, GENERATE_ARRAY(0, 1000000, 10000)).
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data no BigQuery, você pode usar a seguinte sintaxe:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_particionada` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda OPTIONS( description="Tabela de vendas particionada por data" )
Para consultar dados de uma partição específica, a cláusula WHERE é utilizada para filtrar pela coluna de partição:
SELECT produto, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` WHERE data_venda = '2023-01-15' GROUP BY
Este exemplo demonstra como o particionamento permite que o BigQuery escaneie apenas a partição correspondente a '2023-01-15', otimizando a consulta. [1]
Clustering: Organizando os Dados para Acelerar Consultas
Enquanto o particionamento divide uma tabela em segmentos físicos, o clustering (ou agrupamento) organiza os dados dentro dessas partições (ou da tabela inteira, se não particionada) com base em colunas específicas definidas pelo usuário [2]. Pense no particionamento como a criação de gavetas em um armário, e no clustering como a organização dos itens dentro de cada gaveta em uma ordem lógica.
Como Funciona?
O clustering funciona ordenando os blocos de armazenamento de dados com base nos valores das colunas clusterizadas. Quando uma consulta filtra ou agrega dados por essas colunas, o sistema de banco de dados pode escanear apenas os blocos relevantes, em vez de toda a partição ou tabela. Isso é particularmente eficaz para colunas com alta cardinalidade (muitos valores distintos) [2].
Por exemplo, se uma tabela de transações for clusterizada pela coluna customer_id, todas as transações de um mesmo cliente serão armazenadas fisicamente próximas. Uma consulta que busca transações de um customer_id específico se beneficiará enormemente, pois o sistema precisará ler apenas uma pequena porção dos dados.
Benefícios do Clustering
Melhora da Performance em Filtros e Agregações: Acelera consultas que filtram ou agregam dados em colunas clusterizadas, especialmente aquelas com alta cardinalidade.
Redução de Dados Escaneados: Similar ao particionamento, o clustering permite que o sistema ignore blocos de dados irrelevantes, diminuindo a quantidade de dados processados e, consequentemente, os custos [2].
Otimização para Múltiplas Colunas: É possível clusterizar por múltiplas colunas, e a ordem dessas colunas é importante. O sistema otimiza a busca da esquerda para a direita, priorizando a primeira coluna clusterizada [2].
Quando Usar Clustering?
Granularidade Fina: Quando o particionamento não oferece a granularidade necessária para otimizar consultas específicas.
Filtros em Colunas de Alta Cardinalidade: Ideal para colunas com muitos valores distintos, onde o particionamento seria impraticável ou ineficiente.
Consultas com Múltiplos Filtros ou Agregações: Quando as consultas frequentemente utilizam filtros ou agregações em várias colunas [2].
Tabelas ou Partições Grandes: Tabelas ou partições com mais de 64 MB geralmente se beneficiam do clustering [2].
Combinando Particionamento e Clustering
A combinação de particionamento e clustering é uma estratégia poderosa para otimização de desempenho. Primeiro, a tabela é dividida em partições (por exemplo, por data), e então, dentro de cada partição, os dados são clusterizados por uma ou mais colunas (por exemplo, customer_id ou product_category). Isso oferece uma otimização em duas camadas, resultando em um desempenho de consulta ainda melhor [2].
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data e clusterizada por produto e id no BigQuery:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_part_clustered` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda CLUSTER BY produto, id OPTIONS( description="Tabela de vendas particionada por data e clusterizada por produto e id" )
Neste exemplo, os dados são primeiro divididos por data_venda, e dentro de cada partição de data, são organizados por produto e, em seguida, por id. Uma consulta que filtra por data_venda e produto será altamente otimizada. [2]
Tabelas, Views e Materialized Views: Qual a Diferença?
Além de otimizar o armazenamento físico com particionamento e clustering, a modelagem de dados também envolve a escolha da estrutura lógica correta para expor e consumir esses dados. As três principais opções são Tabelas, Views (Visualizações) e Materialized Views (Visualizações Materializadas).
1. Tabelas (Tables)
As tabelas são a estrutura fundamental de armazenamento em qualquer banco de dados relacional ou data warehouse. Elas armazenam os dados fisicamente no disco.
Características: Os dados são persistidos fisicamente. Operações de DML (Insert, Update, Delete) modificam os dados diretamente na tabela.
Performance: A performance de leitura depende de como a tabela está estruturada (índices, particionamento, clustering).
Custo: Você paga pelo armazenamento físico dos dados e pelo processamento das consultas realizadas sobre eles.
Quando usar: Para armazenar os dados brutos ou processados que formam a base do seu data warehouse.
2. Views (Visualizações Lógicas)
Uma View é essencialmente uma consulta SQL salva que atua como uma tabela virtual. Ela não armazena dados fisicamente; em vez disso, a consulta subjacente é executada toda vez que a View é consultada [3].
Características: Não ocupam espaço de armazenamento (além da definição da query). Sempre retornam os dados mais atualizados da(s) tabela(s) base.
Performance: A performance depende inteiramente da complexidade da query subjacente e do volume de dados nas tabelas base no momento da execução. Consultas complexas em Views podem ser lentas.
Custo: Você paga apenas pelo processamento da consulta toda vez que a View é acessada.
Quando usar:
Para simplificar consultas complexas (encapsulando joins e agregações).
Para restringir o acesso a colunas ou linhas específicas de uma tabela base (segurança).
Para criar uma camada de abstração lógica sobre o modelo físico.
Exemplo de Criação de View:
CREATE VIEW `seu_projeto.seu_dataset.view_vendas_diarias` AS SELECT data_venda, SUM(valor) as total_vendas, COUNT(id) as qtd_transacoes FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY
3. Materialized Views (Visualizações Materializadas)
As Materialized Views combinam características de Tabelas e Views. Elas são definidas por uma consulta SQL (como uma View), mas o resultado dessa consulta é pré-computado e armazenado fisicamente no disco (como uma Tabela) [4].
Características: Armazenam dados fisicamente. Precisam ser "atualizadas" (refreshed) para refletir as mudanças nas tabelas base. A atualização pode ser manual, agendada ou automática (incremental), dependendo do banco de dados.
Performance: Oferecem performance de leitura extremamente rápida, pois os dados já estão pré-computados (especialmente útil para agregações pesadas).
Custo: Você paga pelo armazenamento dos dados pré-computados, pelo processamento necessário para atualizar a Materialized View e pelas consultas feitas a ela (que geralmente são muito mais baratas do que consultar as tabelas base).
Quando usar:
Para dashboards e relatórios que exigem tempos de resposta em milissegundos.
Quando uma mesma agregação complexa é consultada repetidamente por múltiplos usuários ou processos.
Quando a latência de dados (dados ligeiramente desatualizados entre os ciclos de atualização) é aceitável [4].
Exemplo de Criação de Materialized View (BigQuery):
CREATE MATERIALIZED VIEW `seu_projeto.seu_dataset.mv_vendas_mensais` AS SELECT EXTRACT(MONTH FROM data_venda) as mes, EXTRACT(YEAR FROM data_venda) as ano, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY mes,
Resumo Comparativo
Característica | Tabela | View | Materialized View |
|---|---|---|---|
Armazenamento | Físico | Lógico (Apenas a Query) | Físico (Pré-computado) |
Freshness dos Dados | Atualizado via DML | Sempre em tempo real | Depende da frequência de atualização (Refresh) |
Performance de Leitura | Alta (se otimizada) | Depende da query base | Muito Alta |
Custos Envolvidos | Armazenamento + Query | Apenas Query | Armazenamento + Refresh + Query (mais barata) |
Conclusão
A modelagem de dados moderna exige um entendimento profundo de como os dados são armazenados e acessados. O particionamento e o clustering são ferramentas indispensáveis para organizar fisicamente grandes volumes de dados, reduzindo custos e acelerando consultas através da minimização da leitura de dados desnecessários.
Por outro lado, a escolha entre Tabelas, Views e Materialized Views define a arquitetura lógica do seu data warehouse. Enquanto as Tabelas guardam a verdade absoluta, as Views oferecem flexibilidade e segurança, e as Materialized Views entregam a performance extrema necessária para análises em larga escala.
Dominar essas técnicas é metade do caminho. A outra metade é garantir que os dados chegam até essas estruturas de forma confiável — sem surpresas, sem black boxes, sem manutenção interminável. É exatamente isso que a Erathos resolve.
Referências
[1] Google Cloud. "Introduction to partitioned tables". Disponível em: https://cloud.google.com/bigquery/docs/partitioned-tables
[2] Google Cloud. "Introduction to clustered tables". Disponível em: https://cloud.google.com/bigquery/docs/clustered-tables
[3] Databricks. "Tables and views in Databricks". Disponível em: https://docs.databricks.com/aws/en/data-engineering/tables-views
[4] Snowflake. "Working with Materialized Views". Disponível em: https://docs.snowflake.com/en/user-guide/views-materialized
Se você já abriu uma query no BigQuery e tomou um susto com o preview de custo antes mesmo de executar — ou recebeu aquela fatura no fim do mês muito maior do que o esperado — você sabe o preço de uma modelagem mal feita. Particionamento, clustering, views e materialized views não são apenas detalhes técnicos: são a diferença entre pipelines que custam centavos e pipelines que drenam o orçamento silenciosamente.
Neste guia, vamos explorar como cada uma dessas técnicas funciona, quando aplicar, e como combiná-las para construir um data warehouse que entrega performance real — sem explodir o cartão de crédito da empresa.
Particionamento: Dividindo para Conquistar
O particionamento é uma técnica de otimização que envolve a divisão física de uma tabela grande em segmentos menores e mais gerenciáveis, chamados partições. Essa divisão é baseada nos valores de uma ou mais colunas da tabela, geralmente colunas de data/hora ou identificadores inteiros [1].
Como Funciona?
Quando uma tabela é particionada, os dados são organizados em blocos de armazenamento separados, onde cada bloco corresponde a uma partição específica. Por exemplo, uma tabela de vendas pode ser particionada por data, com cada dia, mês ou ano armazenado em uma partição distinta. Quando uma consulta é executada com um filtro na coluna de partição, o sistema de banco de dados pode escanear apenas as partições relevantes, ignorando as demais. Esse processo, conhecido como pruning (poda), reduz significativamente a quantidade de dados a serem lidos, resultando em consultas mais rápidas e custos operacionais menores [1].
Benefícios do Particionamento
Melhora da Performance de Consultas: Ao reduzir o volume de dados a serem escaneados, as consultas que utilizam filtros nas colunas de partição são executadas muito mais rapidamente.
Redução de Custos: Muitos data warehouses baseados em nuvem, como o Google BigQuery, cobram com base na quantidade de dados processados. O particionamento minimiza essa quantidade, impactando diretamente nos custos [1].
Gerenciamento Simplificado: Facilita a manutenção da tabela, permitindo operações como exclusão ou expiração de dados em nível de partição, sem afetar o restante da tabela. Isso é particularmente útil para políticas de retenção de dados [1].
Estimativa de Custos de Consulta: Em sistemas como o BigQuery, o particionamento permite uma estimativa mais precisa dos custos de uma consulta antes de sua execução, pois o sistema pode determinar quais partições serão escaneadas [1].
Tipos Comuns de Particionamento
Os tipos de particionamento variam entre as plataformas, mas os mais comuns incluem:
Particionamento por Coluna de Tempo: Baseado em colunas
DATE,TIMESTAMPouDATETIME. Os dados são automaticamente alocados em partições horárias, diárias, mensais ou anuais. Exemplo:PARTITION BY DATE(timestamp_col).Particionamento por Tempo de Ingestão: O sistema atribui automaticamente os dados a partições com base no momento em que são ingeridos. Uma pseudocoluna (ex:
_PARTITIONTIMEno BigQuery) é usada para essa finalidade.Particionamento por Intervalo de Inteiros: Baseado em uma coluna
INTEGER, onde as partições são definidas por intervalos de valores. Exemplo:PARTITION BY RANGE_BUCKET(customer_id, GENERATE_ARRAY(0, 1000000, 10000)).
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data no BigQuery, você pode usar a seguinte sintaxe:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_particionada` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda OPTIONS( description="Tabela de vendas particionada por data" )
Para consultar dados de uma partição específica, a cláusula WHERE é utilizada para filtrar pela coluna de partição:
SELECT produto, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` WHERE data_venda = '2023-01-15' GROUP BY
Este exemplo demonstra como o particionamento permite que o BigQuery escaneie apenas a partição correspondente a '2023-01-15', otimizando a consulta. [1]
Clustering: Organizando os Dados para Acelerar Consultas
Enquanto o particionamento divide uma tabela em segmentos físicos, o clustering (ou agrupamento) organiza os dados dentro dessas partições (ou da tabela inteira, se não particionada) com base em colunas específicas definidas pelo usuário [2]. Pense no particionamento como a criação de gavetas em um armário, e no clustering como a organização dos itens dentro de cada gaveta em uma ordem lógica.
Como Funciona?
O clustering funciona ordenando os blocos de armazenamento de dados com base nos valores das colunas clusterizadas. Quando uma consulta filtra ou agrega dados por essas colunas, o sistema de banco de dados pode escanear apenas os blocos relevantes, em vez de toda a partição ou tabela. Isso é particularmente eficaz para colunas com alta cardinalidade (muitos valores distintos) [2].
Por exemplo, se uma tabela de transações for clusterizada pela coluna customer_id, todas as transações de um mesmo cliente serão armazenadas fisicamente próximas. Uma consulta que busca transações de um customer_id específico se beneficiará enormemente, pois o sistema precisará ler apenas uma pequena porção dos dados.
Benefícios do Clustering
Melhora da Performance em Filtros e Agregações: Acelera consultas que filtram ou agregam dados em colunas clusterizadas, especialmente aquelas com alta cardinalidade.
Redução de Dados Escaneados: Similar ao particionamento, o clustering permite que o sistema ignore blocos de dados irrelevantes, diminuindo a quantidade de dados processados e, consequentemente, os custos [2].
Otimização para Múltiplas Colunas: É possível clusterizar por múltiplas colunas, e a ordem dessas colunas é importante. O sistema otimiza a busca da esquerda para a direita, priorizando a primeira coluna clusterizada [2].
Quando Usar Clustering?
Granularidade Fina: Quando o particionamento não oferece a granularidade necessária para otimizar consultas específicas.
Filtros em Colunas de Alta Cardinalidade: Ideal para colunas com muitos valores distintos, onde o particionamento seria impraticável ou ineficiente.
Consultas com Múltiplos Filtros ou Agregações: Quando as consultas frequentemente utilizam filtros ou agregações em várias colunas [2].
Tabelas ou Partições Grandes: Tabelas ou partições com mais de 64 MB geralmente se beneficiam do clustering [2].
Combinando Particionamento e Clustering
A combinação de particionamento e clustering é uma estratégia poderosa para otimização de desempenho. Primeiro, a tabela é dividida em partições (por exemplo, por data), e então, dentro de cada partição, os dados são clusterizados por uma ou mais colunas (por exemplo, customer_id ou product_category). Isso oferece uma otimização em duas camadas, resultando em um desempenho de consulta ainda melhor [2].
Exemplo de Código (BigQuery SQL)
Para criar uma tabela particionada por data e clusterizada por produto e id no BigQuery:
CREATE TABLE `seu_projeto.seu_dataset.tabela_vendas_part_clustered` ( id STRING, produto STRING, valor NUMERIC, data_venda DATE ) PARTITION BY data_venda CLUSTER BY produto, id OPTIONS( description="Tabela de vendas particionada por data e clusterizada por produto e id" )
Neste exemplo, os dados são primeiro divididos por data_venda, e dentro de cada partição de data, são organizados por produto e, em seguida, por id. Uma consulta que filtra por data_venda e produto será altamente otimizada. [2]
Tabelas, Views e Materialized Views: Qual a Diferença?
Além de otimizar o armazenamento físico com particionamento e clustering, a modelagem de dados também envolve a escolha da estrutura lógica correta para expor e consumir esses dados. As três principais opções são Tabelas, Views (Visualizações) e Materialized Views (Visualizações Materializadas).
1. Tabelas (Tables)
As tabelas são a estrutura fundamental de armazenamento em qualquer banco de dados relacional ou data warehouse. Elas armazenam os dados fisicamente no disco.
Características: Os dados são persistidos fisicamente. Operações de DML (Insert, Update, Delete) modificam os dados diretamente na tabela.
Performance: A performance de leitura depende de como a tabela está estruturada (índices, particionamento, clustering).
Custo: Você paga pelo armazenamento físico dos dados e pelo processamento das consultas realizadas sobre eles.
Quando usar: Para armazenar os dados brutos ou processados que formam a base do seu data warehouse.
2. Views (Visualizações Lógicas)
Uma View é essencialmente uma consulta SQL salva que atua como uma tabela virtual. Ela não armazena dados fisicamente; em vez disso, a consulta subjacente é executada toda vez que a View é consultada [3].
Características: Não ocupam espaço de armazenamento (além da definição da query). Sempre retornam os dados mais atualizados da(s) tabela(s) base.
Performance: A performance depende inteiramente da complexidade da query subjacente e do volume de dados nas tabelas base no momento da execução. Consultas complexas em Views podem ser lentas.
Custo: Você paga apenas pelo processamento da consulta toda vez que a View é acessada.
Quando usar:
Para simplificar consultas complexas (encapsulando joins e agregações).
Para restringir o acesso a colunas ou linhas específicas de uma tabela base (segurança).
Para criar uma camada de abstração lógica sobre o modelo físico.
Exemplo de Criação de View:
CREATE VIEW `seu_projeto.seu_dataset.view_vendas_diarias` AS SELECT data_venda, SUM(valor) as total_vendas, COUNT(id) as qtd_transacoes FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY
3. Materialized Views (Visualizações Materializadas)
As Materialized Views combinam características de Tabelas e Views. Elas são definidas por uma consulta SQL (como uma View), mas o resultado dessa consulta é pré-computado e armazenado fisicamente no disco (como uma Tabela) [4].
Características: Armazenam dados fisicamente. Precisam ser "atualizadas" (refreshed) para refletir as mudanças nas tabelas base. A atualização pode ser manual, agendada ou automática (incremental), dependendo do banco de dados.
Performance: Oferecem performance de leitura extremamente rápida, pois os dados já estão pré-computados (especialmente útil para agregações pesadas).
Custo: Você paga pelo armazenamento dos dados pré-computados, pelo processamento necessário para atualizar a Materialized View e pelas consultas feitas a ela (que geralmente são muito mais baratas do que consultar as tabelas base).
Quando usar:
Para dashboards e relatórios que exigem tempos de resposta em milissegundos.
Quando uma mesma agregação complexa é consultada repetidamente por múltiplos usuários ou processos.
Quando a latência de dados (dados ligeiramente desatualizados entre os ciclos de atualização) é aceitável [4].
Exemplo de Criação de Materialized View (BigQuery):
CREATE MATERIALIZED VIEW `seu_projeto.seu_dataset.mv_vendas_mensais` AS SELECT EXTRACT(MONTH FROM data_venda) as mes, EXTRACT(YEAR FROM data_venda) as ano, SUM(valor) as total_vendas FROM `seu_projeto.seu_dataset.tabela_vendas_particionada` GROUP BY mes,
Resumo Comparativo
Característica | Tabela | View | Materialized View |
|---|---|---|---|
Armazenamento | Físico | Lógico (Apenas a Query) | Físico (Pré-computado) |
Freshness dos Dados | Atualizado via DML | Sempre em tempo real | Depende da frequência de atualização (Refresh) |
Performance de Leitura | Alta (se otimizada) | Depende da query base | Muito Alta |
Custos Envolvidos | Armazenamento + Query | Apenas Query | Armazenamento + Refresh + Query (mais barata) |
Conclusão
A modelagem de dados moderna exige um entendimento profundo de como os dados são armazenados e acessados. O particionamento e o clustering são ferramentas indispensáveis para organizar fisicamente grandes volumes de dados, reduzindo custos e acelerando consultas através da minimização da leitura de dados desnecessários.
Por outro lado, a escolha entre Tabelas, Views e Materialized Views define a arquitetura lógica do seu data warehouse. Enquanto as Tabelas guardam a verdade absoluta, as Views oferecem flexibilidade e segurança, e as Materialized Views entregam a performance extrema necessária para análises em larga escala.
Dominar essas técnicas é metade do caminho. A outra metade é garantir que os dados chegam até essas estruturas de forma confiável — sem surpresas, sem black boxes, sem manutenção interminável. É exatamente isso que a Erathos resolve.
Referências
[1] Google Cloud. "Introduction to partitioned tables". Disponível em: https://cloud.google.com/bigquery/docs/partitioned-tables
[2] Google Cloud. "Introduction to clustered tables". Disponível em: https://cloud.google.com/bigquery/docs/clustered-tables
[3] Databricks. "Tables and views in Databricks". Disponível em: https://docs.databricks.com/aws/en/data-engineering/tables-views
[4] Snowflake. "Working with Materialized Views". Disponível em: https://docs.snowflake.com/en/user-guide/views-materialized