How to Build Reliable Data Pipelines with Delta Live Tables and Medallion Architecture
Delta Live Tables simplifies reliable pipelines in Databricks with Medallion Architecture. Tutorial with Bronze, Silver, Gold, and data quality.

Building Your First Data Pipeline with Medallion Architecture and Delta Live Tables (DLT)
Learn how to build a robust data pipeline using Delta Live Tables (DLT), Medallion Architecture, and unified governance with Unity Catalog in Databricks.
Delta Live Tables (DLT) is Databricks’ declarative framework for building reliable, scalable, and observable data pipelines. Unlike traditional approaches based on scheduled notebooks or isolated SQL scripts, DLT was designed to address a common challenge in analytics environments: the operational complexity of keeping data pipelines consistent over time.
In data engineering projects, it’s common to start with simple transformations using Delta tables and Databricks jobs. However, as data volume grows and pipelines become more critical, challenges start to emerge — such as dependency management, failure handling, data quality validation, schema versioning, and end-to-end observability.
This is where DLT becomes the right choice. By adopting a declarative approach, data engineers describe the desired state of the data — for example, which tables should exist, their quality rules, and their dependencies — while Databricks automatically handles orchestration, infrastructure management, monitoring, and failure recovery.
Recently integrated into Databricks Lakeflow as part of Declarative Pipelines, DLT positions itself as the ideal solution for continuous or recurring pipelines that require reliability, governance, and ease of maintenance. While it doesn’t completely replace other ways of creating tables in Databricks, it stands out in scenarios where predictability, data quality, and observability are essential requirements.
In this article, we explore how to use Delta Live Tables to build well-structured data pipelines, demonstrating in practice how it can be integrated with external ingestion processes and used as the central transformation layer within Databricks.
Unity Catalog and Unified Governance
Unlike legacy architectures that relied on DBFS, modern pipelines operate under Unity Catalog (UC). Unity Catalog provides:
Unified Governance: Centralized access control and automatic data lineage.
Volumes vs. Tables: Unity Catalog distinguishes raw files (Volumes) from processed data registered as managed tables.
Isolation: Easy separation of dev, staging, and prod environments within the same metastore.
What Is Medallion Architecture?
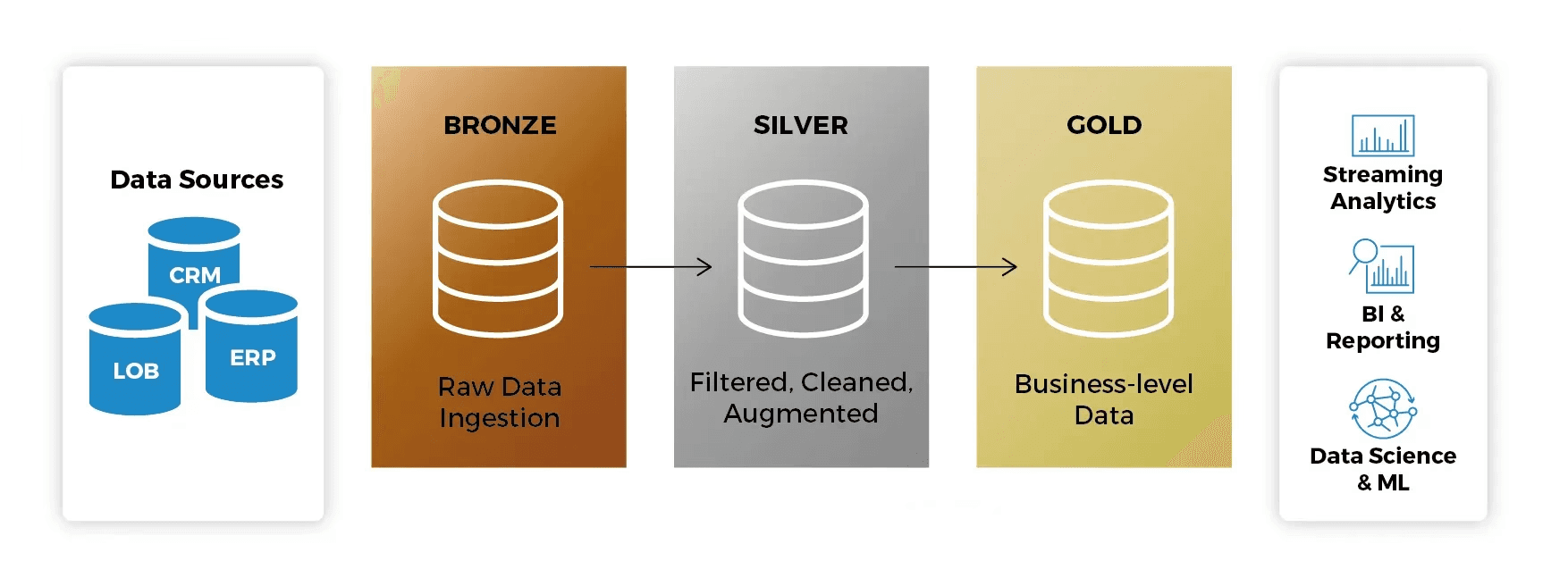
Medallion Architecture describes a series of data layers that represent the quality level of data stored in the Lakehouse:
Bronze: The landing layer. Data is stored in its original format, allowing reprocessing when needed.
Silver: Data is cleaned, normalized, and validated. This is where Expectations (data quality rules) are applied.
Gold: The final layer, with aggregated data ready for consumption by BI analysts and machine learning models.
When using DLT within the Lakeflow ecosystem, you get native observability: Databricks automatically generates the lineage graph and monitors pipeline health without requiring external tools.
Why Use Delta Live Tables?
Infrastructure Management: Databricks automatically scales compute resources.
Native Data Quality: Define Expectations to prevent corrupted data from reaching downstream layers.
Automatic Lineage: Visualize how data flows from source to final consumption.
Streaming and Batch Support: Process data in real time or batch using the same SQL or Python syntax.
For this guide, we use SQL — the most common language for analytical transformations in Databricks — but DLT also fully supports Python.
Assumed Knowledge
To get the most out of this tutorial, you should be familiar with:
Basic SQL concepts
The concept of Medallion Architecture
Basic navigation in the Databricks Workspace
Prerequisites: Preparing the Data Source (MongoDB)
Before starting the data pipeline in Databricks, we need an operational data source. In this tutorial, we use MongoDB Atlas Free Tier as the source database, simulating a real-world transactional data scenario.
Creating a MongoDB Free Tier Cluster
To create a free MongoDB cluster, follow MongoDB’s official tutorials:
Deploy a Free Tier cluster:
https://www.mongodb.com/docs/atlas/tutorial/deploy-free-tier-cluster/Getting started guide:
https://www.mongodb.com/docs/atlas/getting-started/
After creating the cluster, make sure to:
Create a database user
Allow access from your IP (or allow access from all IPs for testing purposes)
Copy the connection string
Step 1: Preparing the Source Data
In this guide, source data is not accessed directly by Databricks through native connectors or Auto Loader. Instead, we use Erathos as the ingestion layer, simulating a modern architecture where ingestion and transformation are clearly separated responsibilities.
Erathos is a data ingestion tool that connects to multiple sources (databases, APIs, and external systems) and delivers data directly into the Lakehouse, abstracting away the complexity of:
Authentication
Incremental extraction
Scheduling
Monitoring
Writing to Delta Lake
Connecting MongoDB to Erathos
Erathos provides a native connector for MongoDB Atlas.
MongoDB connector documentation:
👉 https://docs.erathos.com/connectors/databases/mongodbConnection management:
👉 https://docs.erathos.com/platform/connections
In this step, you will:
Create a connection to MongoDB Atlas using the connection string
Select the desired collection
Define the synchronization mode (full or incremental)
Configuring Databricks as the Destination
After configuring the source, we define Databricks as the destination.
Erathos offers direct integration with Databricks + Unity Catalog, ensuring data arrives already governed in the Lakehouse.
Official documentation:
👉 https://docs.erathos.com/destinations/databricks
In this step, you will:
Provide the Databricks workspace
Select the target catalog and schema
Persist data as Delta tables
Ingestion Result
For this tutorial, Erathos was used to:
Connect to a MongoDB database (demo)
Ingest the collection:
theaters(1,564 records)
Persist the data as Delta tables in Databricks, within a Unity Catalog–governed schema
From this point on, all data processing and transformation is performed exclusively via Delta Live Tables, keeping the focus of this article on transformation and data quality.
Data Governance and Organization
Before starting the DLT pipeline, it’s essential to ensure the target schema already exists in Unity Catalog. DLT strictly follows the hierarchy:
Catalog > Schema > Table
Without a pre-created schema, the pipeline won’t be able to properly register metadata or expose tables for downstream consumption.
Note: In a real-world scenario, Erathos could be ingesting data from transactional databases, APIs, or third-party systems, delivering it directly into a governed Databricks catalog.
Ingestion Strategies: Batch vs. Streaming
Before coding our first layer, it’s important to understand how DLT consumes different types of sources. Regardless of whether data is ingested via Erathos, Auto Loader, or another mechanism, DLT supports both batch and streaming processing.
Auto Loader (Gold Standard)
Used to ingest raw files incrementally using cloud_files. This is the most common approach. You point to a folder in cloud storage (S3, ADLS, GCS) or a Unity Catalog Volume.
How it works: Databricks monitors new file arrivals (JSON, CSV, Parquet) and processes only new files.
Example:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json");
Delta Table (Stream from Table)
If your source is already a Delta table (not just loose files), it must support Change Data Feed (CDF).
How it works: You read the table as a continuous stream.
Example:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table);
Implementation Note:
In this guide, thetheatersdata was ingested beforehand via Erathos and persisted as static Delta tables. For this reason, we useLIVE TABLE(batch). The Medallion Architecture remains the same and can easily be adapted for incremental or streaming sources.
Databricks Technical Requirements
Databricks workspace with Unity Catalog enabled
Permissions to create DLT pipelines and write to a schema in your catalog
Step 2: Creating the Transformation Notebook
In your Workspace, click New > Notebook
Name it
dlt_medallion_pipelineEnsure the default language is SQL
DLT table definitions are declarative and live inside SQL or Python notebooks. Each CREATE OR REFRESH LIVE TABLE command defines what the table should be, while Databricks automatically manages how data is processed, versioned, and optimized.
Bronze Layer
The Bronze layer represents the entry point of data into the Lakehouse. In this scenario, data has already been ingested into Databricks via Erathos, which handles extraction and incremental synchronization from the source system.
The main goal of the Bronze layer is fidelity: capturing data with minimal transformations, preserving the original format, including JSON fields, to ensure traceability and allow future reprocessing.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM erathos_db.erathos_db.theaters
Silver Layer
The Silver layer is where technical complexity increases. Here, we structure data, apply data quality rules, and normalize complex fields like JSON, transforming raw data into a reliable, analytics-ready format.
The location field is stored in the source as a JSON string. In the Silver layer, we use the FROM_JSON function to convert this field into a typed structure (STRUCT), enabling direct access to address attributes and geographic coordinates, as well as enforcing data quality rules.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze );
Expectation Strictness Levels
EXPECT: Generates metrics only. Ideal for understanding data issues without interrupting the pipeline.
DROP ROW: Ensures only trusted data reaches the Silver layer.
FAIL UPDATE: Blocks processing. Critical for scenarios where null data could cause serious issues (e.g., payments or tax calculations).
Expectations also generate automatic metrics in the pipeline, enabling long-term data quality monitoring.
Gold Layer
The Gold layer is optimized for final consumption, providing stable, simple, and high-performance tables for analytics, BI, and downstream applications.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM LIVE.theaters_cleaned_silver;
Autonomous Maintenance (Vacuum and Optimize)
Unlike standard Spark tables, DLT automatically manages OPTIMIZE (small file compaction) and VACUUM (cleanup of old files). This ensures that even with frequent incremental updates, queries against the Gold layer remain performant without manual intervention.
Step 3: Configuring the Pipeline in Unity Catalog
With the code ready, we now create the pipeline object to execute it.
In the sidebar, click Jobs & Pipelines
Under Create New, select ETL pipeline
In the configuration screen, provide a catalog and schema so tables and logs are linked to Unity Catalog
Select Add existing assets to attach the notebook created in Step 2
Modernization Note:
Databricks may show a “Legacy configuration” warning. This happens because Lakeflow favors raw.sqlfiles for DevOps workflows. For this tutorial, we use a Notebook for easier data inspection, but in large-scale production environments, migrating to Workspace Files is recommended.
Step 4: Run and Validate
In the pipeline screen, click Run pipeline
Databricks will spin up a cluster and display the lineage graph (DAG)
Monitor processing: the graph shows how many rows flow from Bronze to Gold
If any row violates the theater_id IS NOT NULL rule in the Silver layer, DLT will drop the row and record the metric in the data quality panel.
Conclusion
You’ve successfully implemented a robust data pipeline using Medallion Architecture and Delta Live Tables within the Databricks Lakeflow ecosystem. By following this guide, you’ve established a solid foundation for modern data engineering, ensuring:
Smart Ingestion: Understanding the flexibility between Auto Loader for raw files and consuming existing Delta tables
Active Governance: Using Expectations to ensure only high-quality data reaches consumption layers, reducing debugging time
Native Performance: Leveraging automatic Optimize and Vacuum to keep Gold-layer queries fast without manual maintenance
Lineage and Transparency: Gaining automatic data lineage through Unity Catalog, simplifying audits and compliance
By integrating an ingestion tool like Erathos with Delta Live Tables, we clearly separate ingestion and transformation responsibilities — resulting in simpler, more governable, and more scalable data pipelines.
Building Your First Data Pipeline with Medallion Architecture and Delta Live Tables (DLT)
Learn how to build a robust data pipeline using Delta Live Tables (DLT), Medallion Architecture, and unified governance with Unity Catalog in Databricks.
Delta Live Tables (DLT) is Databricks’ declarative framework for building reliable, scalable, and observable data pipelines. Unlike traditional approaches based on scheduled notebooks or isolated SQL scripts, DLT was designed to address a common challenge in analytics environments: the operational complexity of keeping data pipelines consistent over time.
In data engineering projects, it’s common to start with simple transformations using Delta tables and Databricks jobs. However, as data volume grows and pipelines become more critical, challenges start to emerge — such as dependency management, failure handling, data quality validation, schema versioning, and end-to-end observability.
This is where DLT becomes the right choice. By adopting a declarative approach, data engineers describe the desired state of the data — for example, which tables should exist, their quality rules, and their dependencies — while Databricks automatically handles orchestration, infrastructure management, monitoring, and failure recovery.
Recently integrated into Databricks Lakeflow as part of Declarative Pipelines, DLT positions itself as the ideal solution for continuous or recurring pipelines that require reliability, governance, and ease of maintenance. While it doesn’t completely replace other ways of creating tables in Databricks, it stands out in scenarios where predictability, data quality, and observability are essential requirements.
In this article, we explore how to use Delta Live Tables to build well-structured data pipelines, demonstrating in practice how it can be integrated with external ingestion processes and used as the central transformation layer within Databricks.
Unity Catalog and Unified Governance
Unlike legacy architectures that relied on DBFS, modern pipelines operate under Unity Catalog (UC). Unity Catalog provides:
Unified Governance: Centralized access control and automatic data lineage.
Volumes vs. Tables: Unity Catalog distinguishes raw files (Volumes) from processed data registered as managed tables.
Isolation: Easy separation of dev, staging, and prod environments within the same metastore.
What Is Medallion Architecture?
Medallion Architecture describes a series of data layers that represent the quality level of data stored in the Lakehouse:
Bronze: The landing layer. Data is stored in its original format, allowing reprocessing when needed.
Silver: Data is cleaned, normalized, and validated. This is where Expectations (data quality rules) are applied.
Gold: The final layer, with aggregated data ready for consumption by BI analysts and machine learning models.
When using DLT within the Lakeflow ecosystem, you get native observability: Databricks automatically generates the lineage graph and monitors pipeline health without requiring external tools.
Why Use Delta Live Tables?
Infrastructure Management: Databricks automatically scales compute resources.
Native Data Quality: Define Expectations to prevent corrupted data from reaching downstream layers.
Automatic Lineage: Visualize how data flows from source to final consumption.
Streaming and Batch Support: Process data in real time or batch using the same SQL or Python syntax.
For this guide, we use SQL — the most common language for analytical transformations in Databricks — but DLT also fully supports Python.
Assumed Knowledge
To get the most out of this tutorial, you should be familiar with:
Basic SQL concepts
The concept of Medallion Architecture
Basic navigation in the Databricks Workspace
Prerequisites: Preparing the Data Source (MongoDB)
Before starting the data pipeline in Databricks, we need an operational data source. In this tutorial, we use MongoDB Atlas Free Tier as the source database, simulating a real-world transactional data scenario.
Creating a MongoDB Free Tier Cluster
To create a free MongoDB cluster, follow MongoDB’s official tutorials:
Deploy a Free Tier cluster:
https://www.mongodb.com/docs/atlas/tutorial/deploy-free-tier-cluster/Getting started guide:
https://www.mongodb.com/docs/atlas/getting-started/
After creating the cluster, make sure to:
Create a database user
Allow access from your IP (or allow access from all IPs for testing purposes)
Copy the connection string
Step 1: Preparing the Source Data
In this guide, source data is not accessed directly by Databricks through native connectors or Auto Loader. Instead, we use Erathos as the ingestion layer, simulating a modern architecture where ingestion and transformation are clearly separated responsibilities.
Erathos is a data ingestion tool that connects to multiple sources (databases, APIs, and external systems) and delivers data directly into the Lakehouse, abstracting away the complexity of:
Authentication
Incremental extraction
Scheduling
Monitoring
Writing to Delta Lake
Connecting MongoDB to Erathos
Erathos provides a native connector for MongoDB Atlas.
MongoDB connector documentation:
👉 https://docs.erathos.com/connectors/databases/mongodbConnection management:
👉 https://docs.erathos.com/platform/connections
In this step, you will:
Create a connection to MongoDB Atlas using the connection string
Select the desired collection
Define the synchronization mode (full or incremental)
Configuring Databricks as the Destination
After configuring the source, we define Databricks as the destination.
Erathos offers direct integration with Databricks + Unity Catalog, ensuring data arrives already governed in the Lakehouse.
Official documentation:
👉 https://docs.erathos.com/destinations/databricks
In this step, you will:
Provide the Databricks workspace
Select the target catalog and schema
Persist data as Delta tables
Ingestion Result
For this tutorial, Erathos was used to:
Connect to a MongoDB database (demo)
Ingest the collection:
theaters(1,564 records)
Persist the data as Delta tables in Databricks, within a Unity Catalog–governed schema
From this point on, all data processing and transformation is performed exclusively via Delta Live Tables, keeping the focus of this article on transformation and data quality.
Data Governance and Organization
Before starting the DLT pipeline, it’s essential to ensure the target schema already exists in Unity Catalog. DLT strictly follows the hierarchy:
Catalog > Schema > Table
Without a pre-created schema, the pipeline won’t be able to properly register metadata or expose tables for downstream consumption.
Note: In a real-world scenario, Erathos could be ingesting data from transactional databases, APIs, or third-party systems, delivering it directly into a governed Databricks catalog.
Ingestion Strategies: Batch vs. Streaming
Before coding our first layer, it’s important to understand how DLT consumes different types of sources. Regardless of whether data is ingested via Erathos, Auto Loader, or another mechanism, DLT supports both batch and streaming processing.
Auto Loader (Gold Standard)
Used to ingest raw files incrementally using cloud_files. This is the most common approach. You point to a folder in cloud storage (S3, ADLS, GCS) or a Unity Catalog Volume.
How it works: Databricks monitors new file arrivals (JSON, CSV, Parquet) and processes only new files.
Example:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json");
Delta Table (Stream from Table)
If your source is already a Delta table (not just loose files), it must support Change Data Feed (CDF).
How it works: You read the table as a continuous stream.
Example:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table);
Implementation Note:
In this guide, thetheatersdata was ingested beforehand via Erathos and persisted as static Delta tables. For this reason, we useLIVE TABLE(batch). The Medallion Architecture remains the same and can easily be adapted for incremental or streaming sources.
Databricks Technical Requirements
Databricks workspace with Unity Catalog enabled
Permissions to create DLT pipelines and write to a schema in your catalog
Step 2: Creating the Transformation Notebook
In your Workspace, click New > Notebook
Name it
dlt_medallion_pipelineEnsure the default language is SQL
DLT table definitions are declarative and live inside SQL or Python notebooks. Each CREATE OR REFRESH LIVE TABLE command defines what the table should be, while Databricks automatically manages how data is processed, versioned, and optimized.
Bronze Layer
The Bronze layer represents the entry point of data into the Lakehouse. In this scenario, data has already been ingested into Databricks via Erathos, which handles extraction and incremental synchronization from the source system.
The main goal of the Bronze layer is fidelity: capturing data with minimal transformations, preserving the original format, including JSON fields, to ensure traceability and allow future reprocessing.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM erathos_db.erathos_db.theaters
Silver Layer
The Silver layer is where technical complexity increases. Here, we structure data, apply data quality rules, and normalize complex fields like JSON, transforming raw data into a reliable, analytics-ready format.
The location field is stored in the source as a JSON string. In the Silver layer, we use the FROM_JSON function to convert this field into a typed structure (STRUCT), enabling direct access to address attributes and geographic coordinates, as well as enforcing data quality rules.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze );
Expectation Strictness Levels
EXPECT: Generates metrics only. Ideal for understanding data issues without interrupting the pipeline.
DROP ROW: Ensures only trusted data reaches the Silver layer.
FAIL UPDATE: Blocks processing. Critical for scenarios where null data could cause serious issues (e.g., payments or tax calculations).
Expectations also generate automatic metrics in the pipeline, enabling long-term data quality monitoring.
Gold Layer
The Gold layer is optimized for final consumption, providing stable, simple, and high-performance tables for analytics, BI, and downstream applications.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM LIVE.theaters_cleaned_silver;
Autonomous Maintenance (Vacuum and Optimize)
Unlike standard Spark tables, DLT automatically manages OPTIMIZE (small file compaction) and VACUUM (cleanup of old files). This ensures that even with frequent incremental updates, queries against the Gold layer remain performant without manual intervention.
Step 3: Configuring the Pipeline in Unity Catalog
With the code ready, we now create the pipeline object to execute it.
In the sidebar, click Jobs & Pipelines
Under Create New, select ETL pipeline
In the configuration screen, provide a catalog and schema so tables and logs are linked to Unity Catalog
Select Add existing assets to attach the notebook created in Step 2
Modernization Note:
Databricks may show a “Legacy configuration” warning. This happens because Lakeflow favors raw.sqlfiles for DevOps workflows. For this tutorial, we use a Notebook for easier data inspection, but in large-scale production environments, migrating to Workspace Files is recommended.
Step 4: Run and Validate
In the pipeline screen, click Run pipeline
Databricks will spin up a cluster and display the lineage graph (DAG)
Monitor processing: the graph shows how many rows flow from Bronze to Gold
If any row violates the theater_id IS NOT NULL rule in the Silver layer, DLT will drop the row and record the metric in the data quality panel.
Conclusion
You’ve successfully implemented a robust data pipeline using Medallion Architecture and Delta Live Tables within the Databricks Lakeflow ecosystem. By following this guide, you’ve established a solid foundation for modern data engineering, ensuring:
Smart Ingestion: Understanding the flexibility between Auto Loader for raw files and consuming existing Delta tables
Active Governance: Using Expectations to ensure only high-quality data reaches consumption layers, reducing debugging time
Native Performance: Leveraging automatic Optimize and Vacuum to keep Gold-layer queries fast without manual maintenance
Lineage and Transparency: Gaining automatic data lineage through Unity Catalog, simplifying audits and compliance
By integrating an ingestion tool like Erathos with Delta Live Tables, we clearly separate ingestion and transformation responsibilities — resulting in simpler, more governable, and more scalable data pipelines.
Building Your First Data Pipeline with Medallion Architecture and Delta Live Tables (DLT)
Learn how to build a robust data pipeline using Delta Live Tables (DLT), Medallion Architecture, and unified governance with Unity Catalog in Databricks.
Delta Live Tables (DLT) is Databricks’ declarative framework for building reliable, scalable, and observable data pipelines. Unlike traditional approaches based on scheduled notebooks or isolated SQL scripts, DLT was designed to address a common challenge in analytics environments: the operational complexity of keeping data pipelines consistent over time.
In data engineering projects, it’s common to start with simple transformations using Delta tables and Databricks jobs. However, as data volume grows and pipelines become more critical, challenges start to emerge — such as dependency management, failure handling, data quality validation, schema versioning, and end-to-end observability.
This is where DLT becomes the right choice. By adopting a declarative approach, data engineers describe the desired state of the data — for example, which tables should exist, their quality rules, and their dependencies — while Databricks automatically handles orchestration, infrastructure management, monitoring, and failure recovery.
Recently integrated into Databricks Lakeflow as part of Declarative Pipelines, DLT positions itself as the ideal solution for continuous or recurring pipelines that require reliability, governance, and ease of maintenance. While it doesn’t completely replace other ways of creating tables in Databricks, it stands out in scenarios where predictability, data quality, and observability are essential requirements.
In this article, we explore how to use Delta Live Tables to build well-structured data pipelines, demonstrating in practice how it can be integrated with external ingestion processes and used as the central transformation layer within Databricks.
Unity Catalog and Unified Governance
Unlike legacy architectures that relied on DBFS, modern pipelines operate under Unity Catalog (UC). Unity Catalog provides:
Unified Governance: Centralized access control and automatic data lineage.
Volumes vs. Tables: Unity Catalog distinguishes raw files (Volumes) from processed data registered as managed tables.
Isolation: Easy separation of dev, staging, and prod environments within the same metastore.
What Is Medallion Architecture?
Medallion Architecture describes a series of data layers that represent the quality level of data stored in the Lakehouse:
Bronze: The landing layer. Data is stored in its original format, allowing reprocessing when needed.
Silver: Data is cleaned, normalized, and validated. This is where Expectations (data quality rules) are applied.
Gold: The final layer, with aggregated data ready for consumption by BI analysts and machine learning models.
When using DLT within the Lakeflow ecosystem, you get native observability: Databricks automatically generates the lineage graph and monitors pipeline health without requiring external tools.
Why Use Delta Live Tables?
Infrastructure Management: Databricks automatically scales compute resources.
Native Data Quality: Define Expectations to prevent corrupted data from reaching downstream layers.
Automatic Lineage: Visualize how data flows from source to final consumption.
Streaming and Batch Support: Process data in real time or batch using the same SQL or Python syntax.
For this guide, we use SQL — the most common language for analytical transformations in Databricks — but DLT also fully supports Python.
Assumed Knowledge
To get the most out of this tutorial, you should be familiar with:
Basic SQL concepts
The concept of Medallion Architecture
Basic navigation in the Databricks Workspace
Prerequisites: Preparing the Data Source (MongoDB)
Before starting the data pipeline in Databricks, we need an operational data source. In this tutorial, we use MongoDB Atlas Free Tier as the source database, simulating a real-world transactional data scenario.
Creating a MongoDB Free Tier Cluster
To create a free MongoDB cluster, follow MongoDB’s official tutorials:
Deploy a Free Tier cluster:
https://www.mongodb.com/docs/atlas/tutorial/deploy-free-tier-cluster/Getting started guide:
https://www.mongodb.com/docs/atlas/getting-started/
After creating the cluster, make sure to:
Create a database user
Allow access from your IP (or allow access from all IPs for testing purposes)
Copy the connection string
Step 1: Preparing the Source Data
In this guide, source data is not accessed directly by Databricks through native connectors or Auto Loader. Instead, we use Erathos as the ingestion layer, simulating a modern architecture where ingestion and transformation are clearly separated responsibilities.
Erathos is a data ingestion tool that connects to multiple sources (databases, APIs, and external systems) and delivers data directly into the Lakehouse, abstracting away the complexity of:
Authentication
Incremental extraction
Scheduling
Monitoring
Writing to Delta Lake
Connecting MongoDB to Erathos
Erathos provides a native connector for MongoDB Atlas.
MongoDB connector documentation:
👉 https://docs.erathos.com/connectors/databases/mongodbConnection management:
👉 https://docs.erathos.com/platform/connections
In this step, you will:
Create a connection to MongoDB Atlas using the connection string
Select the desired collection
Define the synchronization mode (full or incremental)
Configuring Databricks as the Destination
After configuring the source, we define Databricks as the destination.
Erathos offers direct integration with Databricks + Unity Catalog, ensuring data arrives already governed in the Lakehouse.
Official documentation:
👉 https://docs.erathos.com/destinations/databricks
In this step, you will:
Provide the Databricks workspace
Select the target catalog and schema
Persist data as Delta tables
Ingestion Result
For this tutorial, Erathos was used to:
Connect to a MongoDB database (demo)
Ingest the collection:
theaters(1,564 records)
Persist the data as Delta tables in Databricks, within a Unity Catalog–governed schema
From this point on, all data processing and transformation is performed exclusively via Delta Live Tables, keeping the focus of this article on transformation and data quality.
Data Governance and Organization
Before starting the DLT pipeline, it’s essential to ensure the target schema already exists in Unity Catalog. DLT strictly follows the hierarchy:
Catalog > Schema > Table
Without a pre-created schema, the pipeline won’t be able to properly register metadata or expose tables for downstream consumption.
Note: In a real-world scenario, Erathos could be ingesting data from transactional databases, APIs, or third-party systems, delivering it directly into a governed Databricks catalog.
Ingestion Strategies: Batch vs. Streaming
Before coding our first layer, it’s important to understand how DLT consumes different types of sources. Regardless of whether data is ingested via Erathos, Auto Loader, or another mechanism, DLT supports both batch and streaming processing.
Auto Loader (Gold Standard)
Used to ingest raw files incrementally using cloud_files. This is the most common approach. You point to a folder in cloud storage (S3, ADLS, GCS) or a Unity Catalog Volume.
How it works: Databricks monitors new file arrivals (JSON, CSV, Parquet) and processes only new files.
Example:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json");
Delta Table (Stream from Table)
If your source is already a Delta table (not just loose files), it must support Change Data Feed (CDF).
How it works: You read the table as a continuous stream.
Example:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table);
Implementation Note:
In this guide, thetheatersdata was ingested beforehand via Erathos and persisted as static Delta tables. For this reason, we useLIVE TABLE(batch). The Medallion Architecture remains the same and can easily be adapted for incremental or streaming sources.
Databricks Technical Requirements
Databricks workspace with Unity Catalog enabled
Permissions to create DLT pipelines and write to a schema in your catalog
Step 2: Creating the Transformation Notebook
In your Workspace, click New > Notebook
Name it
dlt_medallion_pipelineEnsure the default language is SQL
DLT table definitions are declarative and live inside SQL or Python notebooks. Each CREATE OR REFRESH LIVE TABLE command defines what the table should be, while Databricks automatically manages how data is processed, versioned, and optimized.
Bronze Layer
The Bronze layer represents the entry point of data into the Lakehouse. In this scenario, data has already been ingested into Databricks via Erathos, which handles extraction and incremental synchronization from the source system.
The main goal of the Bronze layer is fidelity: capturing data with minimal transformations, preserving the original format, including JSON fields, to ensure traceability and allow future reprocessing.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM erathos_db.erathos_db.theaters
Silver Layer
The Silver layer is where technical complexity increases. Here, we structure data, apply data quality rules, and normalize complex fields like JSON, transforming raw data into a reliable, analytics-ready format.
The location field is stored in the source as a JSON string. In the Silver layer, we use the FROM_JSON function to convert this field into a typed structure (STRUCT), enabling direct access to address attributes and geographic coordinates, as well as enforcing data quality rules.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze );
Expectation Strictness Levels
EXPECT: Generates metrics only. Ideal for understanding data issues without interrupting the pipeline.
DROP ROW: Ensures only trusted data reaches the Silver layer.
FAIL UPDATE: Blocks processing. Critical for scenarios where null data could cause serious issues (e.g., payments or tax calculations).
Expectations also generate automatic metrics in the pipeline, enabling long-term data quality monitoring.
Gold Layer
The Gold layer is optimized for final consumption, providing stable, simple, and high-performance tables for analytics, BI, and downstream applications.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM LIVE.theaters_cleaned_silver;
Autonomous Maintenance (Vacuum and Optimize)
Unlike standard Spark tables, DLT automatically manages OPTIMIZE (small file compaction) and VACUUM (cleanup of old files). This ensures that even with frequent incremental updates, queries against the Gold layer remain performant without manual intervention.
Step 3: Configuring the Pipeline in Unity Catalog
With the code ready, we now create the pipeline object to execute it.
In the sidebar, click Jobs & Pipelines
Under Create New, select ETL pipeline
In the configuration screen, provide a catalog and schema so tables and logs are linked to Unity Catalog
Select Add existing assets to attach the notebook created in Step 2
Modernization Note:
Databricks may show a “Legacy configuration” warning. This happens because Lakeflow favors raw.sqlfiles for DevOps workflows. For this tutorial, we use a Notebook for easier data inspection, but in large-scale production environments, migrating to Workspace Files is recommended.
Step 4: Run and Validate
In the pipeline screen, click Run pipeline
Databricks will spin up a cluster and display the lineage graph (DAG)
Monitor processing: the graph shows how many rows flow from Bronze to Gold
If any row violates the theater_id IS NOT NULL rule in the Silver layer, DLT will drop the row and record the metric in the data quality panel.
Conclusion
You’ve successfully implemented a robust data pipeline using Medallion Architecture and Delta Live Tables within the Databricks Lakeflow ecosystem. By following this guide, you’ve established a solid foundation for modern data engineering, ensuring:
Smart Ingestion: Understanding the flexibility between Auto Loader for raw files and consuming existing Delta tables
Active Governance: Using Expectations to ensure only high-quality data reaches consumption layers, reducing debugging time
Native Performance: Leveraging automatic Optimize and Vacuum to keep Gold-layer queries fast without manual maintenance
Lineage and Transparency: Gaining automatic data lineage through Unity Catalog, simplifying audits and compliance
By integrating an ingestion tool like Erathos with Delta Live Tables, we clearly separate ingestion and transformation responsibilities — resulting in simpler, more governable, and more scalable data pipelines.
Building Your First Data Pipeline with Medallion Architecture and Delta Live Tables (DLT)
Learn how to build a robust data pipeline using Delta Live Tables (DLT), Medallion Architecture, and unified governance with Unity Catalog in Databricks.
Delta Live Tables (DLT) is Databricks’ declarative framework for building reliable, scalable, and observable data pipelines. Unlike traditional approaches based on scheduled notebooks or isolated SQL scripts, DLT was designed to address a common challenge in analytics environments: the operational complexity of keeping data pipelines consistent over time.
In data engineering projects, it’s common to start with simple transformations using Delta tables and Databricks jobs. However, as data volume grows and pipelines become more critical, challenges start to emerge — such as dependency management, failure handling, data quality validation, schema versioning, and end-to-end observability.
This is where DLT becomes the right choice. By adopting a declarative approach, data engineers describe the desired state of the data — for example, which tables should exist, their quality rules, and their dependencies — while Databricks automatically handles orchestration, infrastructure management, monitoring, and failure recovery.
Recently integrated into Databricks Lakeflow as part of Declarative Pipelines, DLT positions itself as the ideal solution for continuous or recurring pipelines that require reliability, governance, and ease of maintenance. While it doesn’t completely replace other ways of creating tables in Databricks, it stands out in scenarios where predictability, data quality, and observability are essential requirements.
In this article, we explore how to use Delta Live Tables to build well-structured data pipelines, demonstrating in practice how it can be integrated with external ingestion processes and used as the central transformation layer within Databricks.
Unity Catalog and Unified Governance
Unlike legacy architectures that relied on DBFS, modern pipelines operate under Unity Catalog (UC). Unity Catalog provides:
Unified Governance: Centralized access control and automatic data lineage.
Volumes vs. Tables: Unity Catalog distinguishes raw files (Volumes) from processed data registered as managed tables.
Isolation: Easy separation of dev, staging, and prod environments within the same metastore.
What Is Medallion Architecture?
Medallion Architecture describes a series of data layers that represent the quality level of data stored in the Lakehouse:
Bronze: The landing layer. Data is stored in its original format, allowing reprocessing when needed.
Silver: Data is cleaned, normalized, and validated. This is where Expectations (data quality rules) are applied.
Gold: The final layer, with aggregated data ready for consumption by BI analysts and machine learning models.
When using DLT within the Lakeflow ecosystem, you get native observability: Databricks automatically generates the lineage graph and monitors pipeline health without requiring external tools.
Why Use Delta Live Tables?
Infrastructure Management: Databricks automatically scales compute resources.
Native Data Quality: Define Expectations to prevent corrupted data from reaching downstream layers.
Automatic Lineage: Visualize how data flows from source to final consumption.
Streaming and Batch Support: Process data in real time or batch using the same SQL or Python syntax.
For this guide, we use SQL — the most common language for analytical transformations in Databricks — but DLT also fully supports Python.
Assumed Knowledge
To get the most out of this tutorial, you should be familiar with:
Basic SQL concepts
The concept of Medallion Architecture
Basic navigation in the Databricks Workspace
Prerequisites: Preparing the Data Source (MongoDB)
Before starting the data pipeline in Databricks, we need an operational data source. In this tutorial, we use MongoDB Atlas Free Tier as the source database, simulating a real-world transactional data scenario.
Creating a MongoDB Free Tier Cluster
To create a free MongoDB cluster, follow MongoDB’s official tutorials:
Deploy a Free Tier cluster:
https://www.mongodb.com/docs/atlas/tutorial/deploy-free-tier-cluster/Getting started guide:
https://www.mongodb.com/docs/atlas/getting-started/
After creating the cluster, make sure to:
Create a database user
Allow access from your IP (or allow access from all IPs for testing purposes)
Copy the connection string
Step 1: Preparing the Source Data
In this guide, source data is not accessed directly by Databricks through native connectors or Auto Loader. Instead, we use Erathos as the ingestion layer, simulating a modern architecture where ingestion and transformation are clearly separated responsibilities.
Erathos is a data ingestion tool that connects to multiple sources (databases, APIs, and external systems) and delivers data directly into the Lakehouse, abstracting away the complexity of:
Authentication
Incremental extraction
Scheduling
Monitoring
Writing to Delta Lake
Connecting MongoDB to Erathos
Erathos provides a native connector for MongoDB Atlas.
MongoDB connector documentation:
👉 https://docs.erathos.com/connectors/databases/mongodbConnection management:
👉 https://docs.erathos.com/platform/connections
In this step, you will:
Create a connection to MongoDB Atlas using the connection string
Select the desired collection
Define the synchronization mode (full or incremental)
Configuring Databricks as the Destination
After configuring the source, we define Databricks as the destination.
Erathos offers direct integration with Databricks + Unity Catalog, ensuring data arrives already governed in the Lakehouse.
Official documentation:
👉 https://docs.erathos.com/destinations/databricks
In this step, you will:
Provide the Databricks workspace
Select the target catalog and schema
Persist data as Delta tables
Ingestion Result
For this tutorial, Erathos was used to:
Connect to a MongoDB database (demo)
Ingest the collection:
theaters(1,564 records)
Persist the data as Delta tables in Databricks, within a Unity Catalog–governed schema
From this point on, all data processing and transformation is performed exclusively via Delta Live Tables, keeping the focus of this article on transformation and data quality.
Data Governance and Organization
Before starting the DLT pipeline, it’s essential to ensure the target schema already exists in Unity Catalog. DLT strictly follows the hierarchy:
Catalog > Schema > Table
Without a pre-created schema, the pipeline won’t be able to properly register metadata or expose tables for downstream consumption.
Note: In a real-world scenario, Erathos could be ingesting data from transactional databases, APIs, or third-party systems, delivering it directly into a governed Databricks catalog.
Ingestion Strategies: Batch vs. Streaming
Before coding our first layer, it’s important to understand how DLT consumes different types of sources. Regardless of whether data is ingested via Erathos, Auto Loader, or another mechanism, DLT supports both batch and streaming processing.
Auto Loader (Gold Standard)
Used to ingest raw files incrementally using cloud_files. This is the most common approach. You point to a folder in cloud storage (S3, ADLS, GCS) or a Unity Catalog Volume.
How it works: Databricks monitors new file arrivals (JSON, CSV, Parquet) and processes only new files.
Example:
CREATE OR REFRESH STREAMING TABLE taxi_raw_bronze AS SELECT * FROM cloud_files("/Volumes/main/default/my_volume/raw_data/", "json");
Delta Table (Stream from Table)
If your source is already a Delta table (not just loose files), it must support Change Data Feed (CDF).
How it works: You read the table as a continuous stream.
Example:
CREATE OR REFRESH STREAMING TABLE bronze_table AS SELECT * FROM STREAM(catalog.schema.source_delta_table);
Implementation Note:
In this guide, thetheatersdata was ingested beforehand via Erathos and persisted as static Delta tables. For this reason, we useLIVE TABLE(batch). The Medallion Architecture remains the same and can easily be adapted for incremental or streaming sources.
Databricks Technical Requirements
Databricks workspace with Unity Catalog enabled
Permissions to create DLT pipelines and write to a schema in your catalog
Step 2: Creating the Transformation Notebook
In your Workspace, click New > Notebook
Name it
dlt_medallion_pipelineEnsure the default language is SQL
DLT table definitions are declarative and live inside SQL or Python notebooks. Each CREATE OR REFRESH LIVE TABLE command defines what the table should be, while Databricks automatically manages how data is processed, versioned, and optimized.
Bronze Layer
The Bronze layer represents the entry point of data into the Lakehouse. In this scenario, data has already been ingested into Databricks via Erathos, which handles extraction and incremental synchronization from the source system.
The main goal of the Bronze layer is fidelity: capturing data with minimal transformations, preserving the original format, including JSON fields, to ensure traceability and allow future reprocessing.
CREATE OR REFRESH LIVE TABLE theaters_bronze COMMENT "Bronze layer: raw theaters data from Erathos" AS SELECT _id, theater_id, location, _erathos_execution_id, _erathos_synced_at FROM erathos_db.erathos_db.theaters
Silver Layer
The Silver layer is where technical complexity increases. Here, we structure data, apply data quality rules, and normalize complex fields like JSON, transforming raw data into a reliable, analytics-ready format.
The location field is stored in the source as a JSON string. In the Silver layer, we use the FROM_JSON function to convert this field into a typed structure (STRUCT), enabling direct access to address attributes and geographic coordinates, as well as enforcing data quality rules.
CREATE OR REFRESH LIVE TABLE theaters_cleaned_silver ( CONSTRAINT valid_theater_id EXPECT (theater_id IS NOT NULL) ON VIOLATION FAIL UPDATE, CONSTRAINT valid_state EXPECT (state IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_coordinates EXPECT ( latitude IS NOT NULL AND longitude IS NOT NULL ) ) COMMENT "Silver layer: cleaned and structured theaters data" AS SELECT _id, theater_id, location_struct.address.street1 AS street, location_struct.address.city AS city, location_struct.address.state AS state, location_struct.address.zipcode AS zipcode, location_struct.geo.coordinates[0] AS longitude, location_struct.geo.coordinates[1] AS latitude, _erathos_synced_at AS ingested_at FROM ( SELECT *, FROM_JSON( location, 'STRUCT< address: STRUCT< street1: STRING, city: STRING, state: STRING, zipcode: STRING >, geo: STRUCT< type: STRING, coordinates: ARRAY<DOUBLE> > >' ) AS location_struct FROM LIVE.theaters_bronze );
Expectation Strictness Levels
EXPECT: Generates metrics only. Ideal for understanding data issues without interrupting the pipeline.
DROP ROW: Ensures only trusted data reaches the Silver layer.
FAIL UPDATE: Blocks processing. Critical for scenarios where null data could cause serious issues (e.g., payments or tax calculations).
Expectations also generate automatic metrics in the pipeline, enabling long-term data quality monitoring.
Gold Layer
The Gold layer is optimized for final consumption, providing stable, simple, and high-performance tables for analytics, BI, and downstream applications.
CREATE OR REFRESH LIVE TABLE theaters_gold COMMENT "Gold layer: theaters dimension table" AS SELECT theater_id, street, city, state, zipcode, latitude, longitude FROM LIVE.theaters_cleaned_silver;
Autonomous Maintenance (Vacuum and Optimize)
Unlike standard Spark tables, DLT automatically manages OPTIMIZE (small file compaction) and VACUUM (cleanup of old files). This ensures that even with frequent incremental updates, queries against the Gold layer remain performant without manual intervention.
Step 3: Configuring the Pipeline in Unity Catalog
With the code ready, we now create the pipeline object to execute it.
In the sidebar, click Jobs & Pipelines
Under Create New, select ETL pipeline
In the configuration screen, provide a catalog and schema so tables and logs are linked to Unity Catalog
Select Add existing assets to attach the notebook created in Step 2
Modernization Note:
Databricks may show a “Legacy configuration” warning. This happens because Lakeflow favors raw.sqlfiles for DevOps workflows. For this tutorial, we use a Notebook for easier data inspection, but in large-scale production environments, migrating to Workspace Files is recommended.
Step 4: Run and Validate
In the pipeline screen, click Run pipeline
Databricks will spin up a cluster and display the lineage graph (DAG)
Monitor processing: the graph shows how many rows flow from Bronze to Gold
If any row violates the theater_id IS NOT NULL rule in the Silver layer, DLT will drop the row and record the metric in the data quality panel.
Conclusion
You’ve successfully implemented a robust data pipeline using Medallion Architecture and Delta Live Tables within the Databricks Lakeflow ecosystem. By following this guide, you’ve established a solid foundation for modern data engineering, ensuring:
Smart Ingestion: Understanding the flexibility between Auto Loader for raw files and consuming existing Delta tables
Active Governance: Using Expectations to ensure only high-quality data reaches consumption layers, reducing debugging time
Native Performance: Leveraging automatic Optimize and Vacuum to keep Gold-layer queries fast without manual maintenance
Lineage and Transparency: Gaining automatic data lineage through Unity Catalog, simplifying audits and compliance
By integrating an ingestion tool like Erathos with Delta Live Tables, we clearly separate ingestion and transformation responsibilities — resulting in simpler, more governable, and more scalable data pipelines.