Extract data from diverse sources efficiently
Extracting data from various sources is essential for analysis. Learn how to extract data from multiple sources quickly and efficiently.

The Importance of Data Extraction for Efficient Integration
Extracting data from multiple sources is a critical step for data-driven companies looking to consolidate information with security and consistency. Here, you will understand each stage of the process, the main challenges, and learn how Erathos enables you to build automated pipelines to connect multiple data sources and data types to a Data Warehouse, simplifying your flow from start to finish. Curious to know how to turn manual extractions into efficient automations? Keep reading and discover how Erathos can transform your integration landscape.
Why extracting data from multiple sources is important
Unifying Dispersed Data for Agile Decision-Making
In the corporate environment, it is common for data to be scattered across different places: isolated spreadsheets, internal databases, and even legacy systems. This fragmentation makes it difficult to achieve the consolidated view that leaders and analysts need to make fast, accurate decisions. To solve this, it is essential to extract data from multiple sources and bring it together in a single Data Warehouse, turning disconnected data into valuable information.
Adding data means adding growth potential.
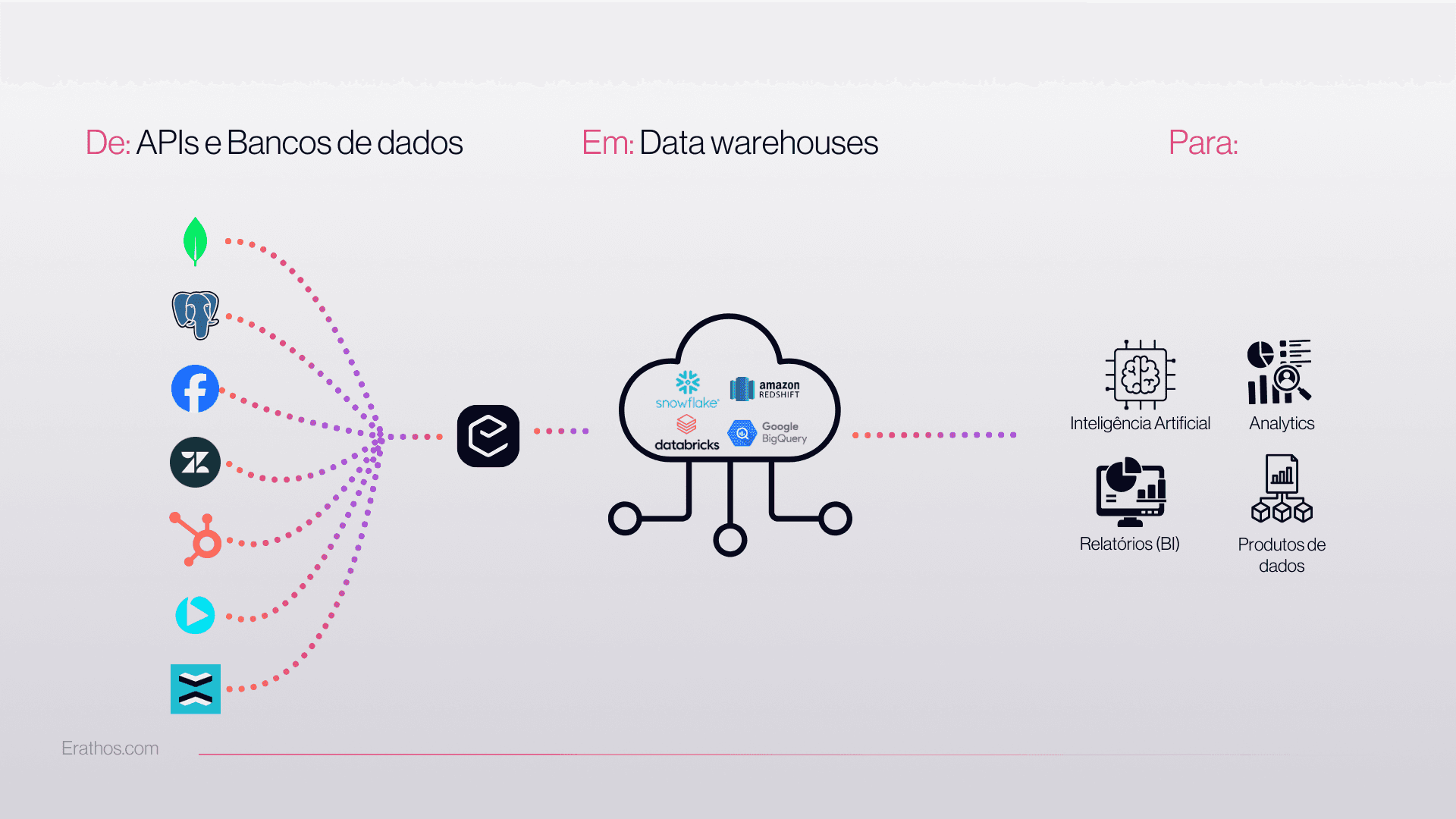
When each area of the company uses a different tool to store information, how can you get fast insights? The answer is unification. Only then does data gain value, context, and become ready to generate answers at the right moment. This is not just about organization—it is a true competitive advantage.
Foundation for reliable analysis
Has this ever happened to you? Different results for the same KPI, depending on where the information comes from. This is a direct reflection of misalignment between data sources. By consolidating multiple sources in one place, you ensure integrity. It becomes easy to compare time periods, cross-reference business areas, and trust what the data is telling you.
This is an essential preparatory step for strategic analysis, predictive modeling, or even tax reporting. Without a single reliable foundation, any decision becomes risky.
Main corporate data sources
The variety of data sources in B2B companies is vast. Knowing how to identify each one and understand how they can be connected is a fundamental part of the path to automation.
Relational databases
Relational databases are pillars in virtually every digital operation. Tools like MySQL, PostgreSQL, and Microsoft SQL Server store information in a structured way, enabling fast queries and SQL-based integrations—understand what SQL is.
The main challenge is usually the complexity of schemas and access controls, along with configuration nuances required to allow uninterrupted transfers. A well-designed pipeline understands these differences and resolves them before bottlenecks appear.
APIs and logs
With accelerated digitization, APIs have become a direct bridge between systems. They deliver data in standardized formats, such as JSON or XML, and make it possible to collect information from SaaS applications, payment platforms, CRMs, and many other touchpoints.
Logs, increasingly strategic, record system events—whether from internal apps, web servers, or infrastructure. Extracting these sources can be recurring or event-based, requiring strong connection mechanisms and volume control.
Spreadsheets and legacy systems
Spreadsheets remain “unsung heroes” behind corporate operations. Many decisions depend on data manually saved by teams in Excel or Google Sheets. It is not uncommon for a company to store vital historical data in files scattered around.
Legacy systems, on the other hand, usually do not offer modern interfaces. What matters is this: hundreds of companies still run on old applications, without APIs, that need to be connected to today’s ecosystem. It is a challenge, but not impossible.
Common challenges when extracting data from different sources
Building a “bridge” between multiple platforms and ensuring everything reaches the Data Warehouse correctly can be more complex than it seems. Let’s go over the main obstacles found along the way.
Inconsistent formats and types
Data sources rarely speak the same language. The same field can appear with different names across systems. While one database uses “customer_id,” another may use “id_customer.” There are also different formats, such as CSV, JSON, or TXT, and each requires care when sending to the destination.
This misalignment can cause failures or duplicate information later on. That is why standardization in integration, even without transforming data, is the first step to ensuring quality.
Variable frequencies and volumes
Not every data source delivers the same volume, or at the same speed. Some sources need updates every minute. Others, only once a day. Some records arrive in large batches all at once, while others trickle in gradually.
Volume and velocity never signal a problem. They demand automation.
Well-designed pipelines account for these differences, creating flexible schedules and checkpoints that do not block the entire flow if one source is delayed.
Authentication and performance issues
There is no point trying to query an ERP, a financial system, or a database if credentials are not aligned. Authentication is key and can vary: tokens, OAuth, digital certificates, and other mechanisms are used to protect access. And of course, access limits and lockouts must always be monitored.
In addition, process performance needs close attention. Large extractions without planning can overload servers, consume bandwidth, or even cause packet loss. Monitoring and tuning query pace is part of the secret.
Best practices for extracting data from multiple sources
Understanding where the challenges are already helps a lot, but having a method is what allows the process to scale and avoid unpleasant “surprises” along the way.
Pipeline standardization
Before building any automation, mapping sources and aligning field naming standards saves dozens of hours of rework. Defining templates for table names, required fields, and file structure makes each new integration more accessible to different areas of the company.
Create an “inventory” of sources: databases, APIs, spreadsheets, legacy systems.
Establish minimum standards for the pipeline.
Document each connection: who approved it, what I extract, and at what frequency.
Even if typing is handled more broadly, as Erathos does, ensuring field standardization already solves much of the puzzle.
Automation and continuous monitoring
Manual extraction? No way. With automated pipelines, the risk of error or omission drops dramatically. The secret is to schedule consistent flows and rely on tools that monitor the process, issue alerts, and store detailed metrics.
Adopt alerts for failures or delays
Implement simple flow health metrics: number of files, average time, latest run
Clearly define who on the team is responsible for potential incidents
Modern tools like Erathos invest in user experience, even for users who are not always technical, to simplify configurations and enable quick adjustments. This greatly increases reliability without depending on hours of internal development, as is common with less intuitive alternatives.
How Erathos makes automated data extraction easier
Imagine creating an automation to collect information from different sources, configure schedules, and monitor everything without needing scripts. That is the ideal scenario—and it is what Erathos delivers.
Zero code: allows business teams to configure integrations in just a few clicks.
Smart scheduling: customize frequency for each source, aligned with business needs.
Real-time monitoring: receive alerts when any flow fails, with clear history for analysis.
Infrastructure-flexible: connects cloud, on-premises, and hybrid environments.
Unlike some competitors that limit integrations to the cloud or require technical knowledge to manipulate scripts, Erathos focuses on accessibility and true automation. The result? Less dependency on the IT team and more autonomy for business areas to innovate quickly.
Automation is within reach of every team. You just need to choose the right tool.
With that, data extraction stops being a long project and becomes part of day-to-day operations, keeping your Data Warehouse updated for real analytics—wherever and whenever needed.
FAQ about data extraction
How do you extract data from different sources?
Extracting data from different sources can start by mapping where each relevant piece of information is stored: databases, APIs, spreadsheets, or legacy systems. Then, it is important to identify how to access each one (SQL queries, API calls, direct file reading) and create a routine that ensures consistency. The ideal approach is to automate this process using tools like Erathos, which lets you build flows and connect multiple sources in a simple and secure way.
What tools should you use to extract data from multiple sources?
When it comes to extracting data from multiple sources, the market offers a variety of options. Some companies choose traditional tools that require programming knowledge, while others explore more intuitive solutions like Erathos. What truly sets Erathos apart is its ease of use, fully automated pipelines, and flexibility to operate both in the cloud and in internal environments. This way, you can extract, load, and monitor data across multiple destinations—all without headaches.
Why integrate data from multiple sources?
Integrating data from multiple sources allows your company to see the whole picture instead of isolated parts. This provides more analytical clarity, reduces inconsistencies, and opens space for strategic discoveries. Decisions become faster and better grounded because all departments look at the same source of truth. It is the beginning of the virtuous cycle of data intelligence.
Is data from all sources compatible?
Not always. There are often differences in how data is stored or named depending on the source system. That is why it is necessary to adopt practices that standardize, document, and validate these differences. By using integration-focused platforms like Erathos, this challenge becomes smaller, since a large part of compatibility work is handled internally by the solution.
What are common challenges in data extraction?
Some of the most frequent challenges are: format differences across sources, unpredictable data volume, weak authentication, access limitations, and the need for constant monitoring. If the process is not automated and well documented, the risk of losing information or creating rework increases significantly. These difficulties justify using solutions specifically designed to extract and integrate data across multiple environments, like Erathos, which provides control and security with real-time monitoring.
Transform Your Data Integration with Erathos
Extracting data from multiple sources and keeping it updated in a Data Warehouse used to be a challenge full of manual scripts and frustration. But now, automation, clarity, and security are within reach for teams of all sizes—as long as they choose the right partners for this journey.
Erathos was created specifically to simplify and automate the process of extracting and integrating data from multiple sources, putting autonomy and monitoring in the user’s hands. This allows IT to breathe easier, while business areas gain the freedom to develop new solutions from a reliable foundation.
Want to discover how Erathos can revolutionize the way your company extracts data from multiple sources?
Talk to our specialists and discover a new standard of automation and trust for your pipelines.
The Importance of Data Extraction for Efficient Integration
Extracting data from multiple sources is a critical step for data-driven companies looking to consolidate information with security and consistency. Here, you will understand each stage of the process, the main challenges, and learn how Erathos enables you to build automated pipelines to connect multiple data sources and data types to a Data Warehouse, simplifying your flow from start to finish. Curious to know how to turn manual extractions into efficient automations? Keep reading and discover how Erathos can transform your integration landscape.
Why extracting data from multiple sources is important
Unifying Dispersed Data for Agile Decision-Making
In the corporate environment, it is common for data to be scattered across different places: isolated spreadsheets, internal databases, and even legacy systems. This fragmentation makes it difficult to achieve the consolidated view that leaders and analysts need to make fast, accurate decisions. To solve this, it is essential to extract data from multiple sources and bring it together in a single Data Warehouse, turning disconnected data into valuable information.
Adding data means adding growth potential.
When each area of the company uses a different tool to store information, how can you get fast insights? The answer is unification. Only then does data gain value, context, and become ready to generate answers at the right moment. This is not just about organization—it is a true competitive advantage.
Foundation for reliable analysis
Has this ever happened to you? Different results for the same KPI, depending on where the information comes from. This is a direct reflection of misalignment between data sources. By consolidating multiple sources in one place, you ensure integrity. It becomes easy to compare time periods, cross-reference business areas, and trust what the data is telling you.
This is an essential preparatory step for strategic analysis, predictive modeling, or even tax reporting. Without a single reliable foundation, any decision becomes risky.
Main corporate data sources
The variety of data sources in B2B companies is vast. Knowing how to identify each one and understand how they can be connected is a fundamental part of the path to automation.
Relational databases
Relational databases are pillars in virtually every digital operation. Tools like MySQL, PostgreSQL, and Microsoft SQL Server store information in a structured way, enabling fast queries and SQL-based integrations—understand what SQL is.
The main challenge is usually the complexity of schemas and access controls, along with configuration nuances required to allow uninterrupted transfers. A well-designed pipeline understands these differences and resolves them before bottlenecks appear.
APIs and logs
With accelerated digitization, APIs have become a direct bridge between systems. They deliver data in standardized formats, such as JSON or XML, and make it possible to collect information from SaaS applications, payment platforms, CRMs, and many other touchpoints.
Logs, increasingly strategic, record system events—whether from internal apps, web servers, or infrastructure. Extracting these sources can be recurring or event-based, requiring strong connection mechanisms and volume control.
Spreadsheets and legacy systems
Spreadsheets remain “unsung heroes” behind corporate operations. Many decisions depend on data manually saved by teams in Excel or Google Sheets. It is not uncommon for a company to store vital historical data in files scattered around.
Legacy systems, on the other hand, usually do not offer modern interfaces. What matters is this: hundreds of companies still run on old applications, without APIs, that need to be connected to today’s ecosystem. It is a challenge, but not impossible.
Common challenges when extracting data from different sources
Building a “bridge” between multiple platforms and ensuring everything reaches the Data Warehouse correctly can be more complex than it seems. Let’s go over the main obstacles found along the way.
Inconsistent formats and types
Data sources rarely speak the same language. The same field can appear with different names across systems. While one database uses “customer_id,” another may use “id_customer.” There are also different formats, such as CSV, JSON, or TXT, and each requires care when sending to the destination.
This misalignment can cause failures or duplicate information later on. That is why standardization in integration, even without transforming data, is the first step to ensuring quality.
Variable frequencies and volumes
Not every data source delivers the same volume, or at the same speed. Some sources need updates every minute. Others, only once a day. Some records arrive in large batches all at once, while others trickle in gradually.
Volume and velocity never signal a problem. They demand automation.
Well-designed pipelines account for these differences, creating flexible schedules and checkpoints that do not block the entire flow if one source is delayed.
Authentication and performance issues
There is no point trying to query an ERP, a financial system, or a database if credentials are not aligned. Authentication is key and can vary: tokens, OAuth, digital certificates, and other mechanisms are used to protect access. And of course, access limits and lockouts must always be monitored.
In addition, process performance needs close attention. Large extractions without planning can overload servers, consume bandwidth, or even cause packet loss. Monitoring and tuning query pace is part of the secret.
Best practices for extracting data from multiple sources
Understanding where the challenges are already helps a lot, but having a method is what allows the process to scale and avoid unpleasant “surprises” along the way.
Pipeline standardization
Before building any automation, mapping sources and aligning field naming standards saves dozens of hours of rework. Defining templates for table names, required fields, and file structure makes each new integration more accessible to different areas of the company.
Create an “inventory” of sources: databases, APIs, spreadsheets, legacy systems.
Establish minimum standards for the pipeline.
Document each connection: who approved it, what I extract, and at what frequency.
Even if typing is handled more broadly, as Erathos does, ensuring field standardization already solves much of the puzzle.
Automation and continuous monitoring
Manual extraction? No way. With automated pipelines, the risk of error or omission drops dramatically. The secret is to schedule consistent flows and rely on tools that monitor the process, issue alerts, and store detailed metrics.
Adopt alerts for failures or delays
Implement simple flow health metrics: number of files, average time, latest run
Clearly define who on the team is responsible for potential incidents
Modern tools like Erathos invest in user experience, even for users who are not always technical, to simplify configurations and enable quick adjustments. This greatly increases reliability without depending on hours of internal development, as is common with less intuitive alternatives.
How Erathos makes automated data extraction easier
Imagine creating an automation to collect information from different sources, configure schedules, and monitor everything without needing scripts. That is the ideal scenario—and it is what Erathos delivers.
Zero code: allows business teams to configure integrations in just a few clicks.
Smart scheduling: customize frequency for each source, aligned with business needs.
Real-time monitoring: receive alerts when any flow fails, with clear history for analysis.
Infrastructure-flexible: connects cloud, on-premises, and hybrid environments.
Unlike some competitors that limit integrations to the cloud or require technical knowledge to manipulate scripts, Erathos focuses on accessibility and true automation. The result? Less dependency on the IT team and more autonomy for business areas to innovate quickly.
Automation is within reach of every team. You just need to choose the right tool.
With that, data extraction stops being a long project and becomes part of day-to-day operations, keeping your Data Warehouse updated for real analytics—wherever and whenever needed.
FAQ about data extraction
How do you extract data from different sources?
Extracting data from different sources can start by mapping where each relevant piece of information is stored: databases, APIs, spreadsheets, or legacy systems. Then, it is important to identify how to access each one (SQL queries, API calls, direct file reading) and create a routine that ensures consistency. The ideal approach is to automate this process using tools like Erathos, which lets you build flows and connect multiple sources in a simple and secure way.
What tools should you use to extract data from multiple sources?
When it comes to extracting data from multiple sources, the market offers a variety of options. Some companies choose traditional tools that require programming knowledge, while others explore more intuitive solutions like Erathos. What truly sets Erathos apart is its ease of use, fully automated pipelines, and flexibility to operate both in the cloud and in internal environments. This way, you can extract, load, and monitor data across multiple destinations—all without headaches.
Why integrate data from multiple sources?
Integrating data from multiple sources allows your company to see the whole picture instead of isolated parts. This provides more analytical clarity, reduces inconsistencies, and opens space for strategic discoveries. Decisions become faster and better grounded because all departments look at the same source of truth. It is the beginning of the virtuous cycle of data intelligence.
Is data from all sources compatible?
Not always. There are often differences in how data is stored or named depending on the source system. That is why it is necessary to adopt practices that standardize, document, and validate these differences. By using integration-focused platforms like Erathos, this challenge becomes smaller, since a large part of compatibility work is handled internally by the solution.
What are common challenges in data extraction?
Some of the most frequent challenges are: format differences across sources, unpredictable data volume, weak authentication, access limitations, and the need for constant monitoring. If the process is not automated and well documented, the risk of losing information or creating rework increases significantly. These difficulties justify using solutions specifically designed to extract and integrate data across multiple environments, like Erathos, which provides control and security with real-time monitoring.
Transform Your Data Integration with Erathos
Extracting data from multiple sources and keeping it updated in a Data Warehouse used to be a challenge full of manual scripts and frustration. But now, automation, clarity, and security are within reach for teams of all sizes—as long as they choose the right partners for this journey.
Erathos was created specifically to simplify and automate the process of extracting and integrating data from multiple sources, putting autonomy and monitoring in the user’s hands. This allows IT to breathe easier, while business areas gain the freedom to develop new solutions from a reliable foundation.
Want to discover how Erathos can revolutionize the way your company extracts data from multiple sources?
Talk to our specialists and discover a new standard of automation and trust for your pipelines.