Data Observability: Breaking the Firefighting Cycle
Learn how to break the cycle of frustration. Discover the best data observability practices for your business.

If you’re a data professional and have never received a message like this, cast the first stone!

First of all, I want to explain why this is a bigger problem than you might think…
When we receive a message like this, we’re spending the scarcest resource data teams have: trust.
Imagine the sales manager (let’s call him João) told us that his team’s main dashboard is broken. João most likely has a lot on his plate, and as a result his schedule is very tight. When he accesses a data team product, he not only needs the information that dashboard should present, but he also needs to take action based on that information. After all, that’s what being data-driven means, right? Making decisions/actions based on data.
Some actions can be taken without data input, but others—like paying sales team commissions—will very likely be blocked until the data team fixes the issue.
Notice that in this hypothetical situation, beyond leaving João stranded, we abruptly interrupt his journey, creating friction that can get much worse during the ticket resolution process—but that’s a topic for another article.
Cases like João’s are recurring. According to research by Dun & Bradstreet ( The Past, Present and Future of Data ), 42% of companies have already faced issues with inconsistent data.
There are countless reasons that lead to data issues, generally grouped into regulatory issues, business demand, human error, interpretation error, and data drift. It’s important to understand these issues as something that comes with data projects, not as incompetence from the team or the developed solution. And this Google article even points out that there is a 92% prevalence of data issues occurring in a project.
What makes these situations hard to handle is that a dataset by itself doesn’t generate exceptions, no matter how wrong that dataset is—the inconsistency is only discovered when it is used. Andy Petrella, author of the book Fundamentals of Data Observability, goes even further by calling data a “Silent Killer,” since situations like this result in an overall slowdown, destruction of trust, and increased stress, anger, and anxiety, without any warning alert.
The goal of Observability—and of this article specifically in the context of data—is to inform an observer about a system’s status. For that, we use 3 main components: logs, traces, and metrics, tracking the execution of the different stages of a data pipeline and generating alerts if any rule is not respected.
In the previous example, when we were told the sales dashboard had inconsistencies, to solve the issue we would have to explore each stage of the data stack until we identified the error. Is it in the dashboard? In the Data Warehouse? Did the ELT run correctly? There are many stages to investigate, but if we use observability instruments, we can identify these inconsistencies before our users even notice them.
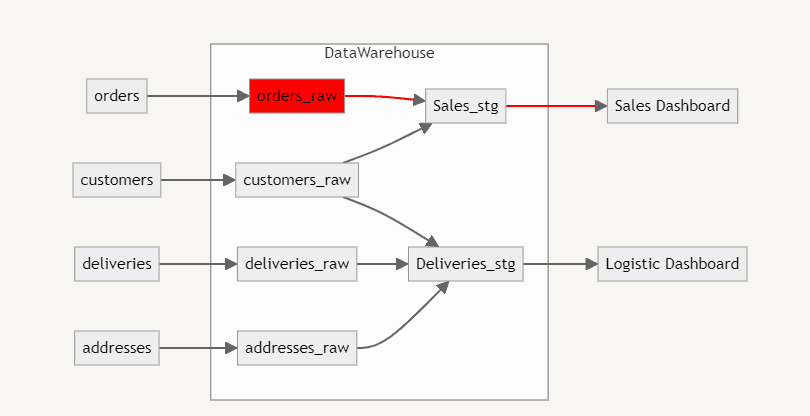
Imagine you received an alert that there is an inconsistency in the orders_raw table and, as a consequence, all dependent stages will not be updated. From this notification, we can inform the team that the sales dashboard is outdated and also provide an estimated fix time. These are stressful situations avoided purely because we received an alert about an error in the data pipeline.
The main rule that should always be followed when implementing alerts is: if an alert is generated, an action must be taken. If you’ve never muted a Slack notifications channel, cast the first stone (we’re running out of stones already hahaha).
Following this rule ensures alerts are not seen as something negative by the team, but rather as a channel of critical information for data operations. There are several tools that can be used to make observability implementation in data pipelines easier: DBT has several features such as tests and the newly launched unit test (available in v.18). Another solution that enables monitoring is Great Expectations, which allows building data contracts and generates an alert if any of them is violated.
We hope this content contributed in some way! If you want to learn more about Erathos, try the platform for free here!
If you’re a data professional and have never received a message like this, cast the first stone!
First of all, I want to explain why this is a bigger problem than you might think…
When we receive a message like this, we’re spending the scarcest resource data teams have: trust.
Imagine the sales manager (let’s call him João) told us that his team’s main dashboard is broken. João most likely has a lot on his plate, and as a result his schedule is very tight. When he accesses a data team product, he not only needs the information that dashboard should present, but he also needs to take action based on that information. After all, that’s what being data-driven means, right? Making decisions/actions based on data.
Some actions can be taken without data input, but others—like paying sales team commissions—will very likely be blocked until the data team fixes the issue.
Notice that in this hypothetical situation, beyond leaving João stranded, we abruptly interrupt his journey, creating friction that can get much worse during the ticket resolution process—but that’s a topic for another article.
Cases like João’s are recurring. According to research by Dun & Bradstreet ( The Past, Present and Future of Data ), 42% of companies have already faced issues with inconsistent data.
There are countless reasons that lead to data issues, generally grouped into regulatory issues, business demand, human error, interpretation error, and data drift. It’s important to understand these issues as something that comes with data projects, not as incompetence from the team or the developed solution. And this Google article even points out that there is a 92% prevalence of data issues occurring in a project.
What makes these situations hard to handle is that a dataset by itself doesn’t generate exceptions, no matter how wrong that dataset is—the inconsistency is only discovered when it is used. Andy Petrella, author of the book Fundamentals of Data Observability, goes even further by calling data a “Silent Killer,” since situations like this result in an overall slowdown, destruction of trust, and increased stress, anger, and anxiety, without any warning alert.
The goal of Observability—and of this article specifically in the context of data—is to inform an observer about a system’s status. For that, we use 3 main components: logs, traces, and metrics, tracking the execution of the different stages of a data pipeline and generating alerts if any rule is not respected.
In the previous example, when we were told the sales dashboard had inconsistencies, to solve the issue we would have to explore each stage of the data stack until we identified the error. Is it in the dashboard? In the Data Warehouse? Did the ELT run correctly? There are many stages to investigate, but if we use observability instruments, we can identify these inconsistencies before our users even notice them.
Imagine you received an alert that there is an inconsistency in the orders_raw table and, as a consequence, all dependent stages will not be updated. From this notification, we can inform the team that the sales dashboard is outdated and also provide an estimated fix time. These are stressful situations avoided purely because we received an alert about an error in the data pipeline.
The main rule that should always be followed when implementing alerts is: if an alert is generated, an action must be taken. If you’ve never muted a Slack notifications channel, cast the first stone (we’re running out of stones already hahaha).
Following this rule ensures alerts are not seen as something negative by the team, but rather as a channel of critical information for data operations. There are several tools that can be used to make observability implementation in data pipelines easier: DBT has several features such as tests and the newly launched unit test (available in v.18). Another solution that enables monitoring is Great Expectations, which allows building data contracts and generates an alert if any of them is violated.
We hope this content contributed in some way! If you want to learn more about Erathos, try the platform for free here!