Build a Modern Data Stack for Zero Cost: The Essential Guide for Data Teams
Build a functional Modern Data Stack at zero cost using Erathos, BigQuery Sandbox, and free BI tools. A guide for teams with no budget.

Introduction: Unlocking the Value of Data Without Blowing the Budget
In today’s data-driven landscape, the ability to collect, store, process, and visualize information is crucial for any business seeking innovation and competitive advantage. However, the common perception is that building a modern data stack requires significant investments in software licenses, infrastructure, and specialized resources. But what if we told you it’s possible to start this journey at zero cost, creating a solid foundation for future growth?
This detailed guide will show how data teams can build a robust and efficient stack using free and open-source tools, with a focus on maximizing business value from day one. Our goal is to demystify complexity and cost, proving that you don’t need astronomical budgets to start extracting valuable insights from your data.
The Pillars of Your Free Data Stack
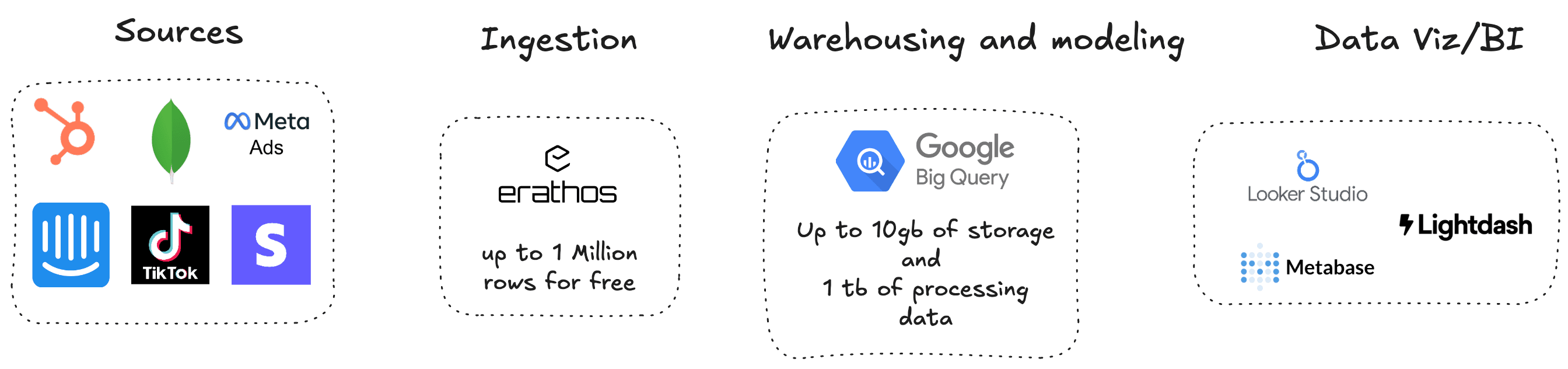
Let’s explore the tools that make up our zero-cost modern data stack, highlighting their capabilities and how they integrate to form a powerful ecosystem.
1. Data Ingestion: Erathos (Free Tier)
The first step in any data journey is ingestion. We need a tool that can collect data from various sources and transport it to our storage environment reliably and efficiently. For this, Erathos offers an ideal solution with its free tier. Erathos already has more than 70 available connectors and allows data to be centralized in BigQuery, Databricks, redshift, S3 Icerberg or postgres.
•Free Tier Capabilities: Up to 1 million monthly rows and 5 pipeline jobs. This is more than enough for many startups and small businesses to begin collecting critical data from their operations, such as application logs, sales data, or user interactions.
•Benefits: Erathos simplifies the creation of data pipelines, allowing you to configure ingestion quickly without the need to write complex code. Its intuitive interface and ability to manage multiple connectors make data collection an accessible task, even for teams with limited resources.
2. Storage and Modeling: Google BigQuery (Free Tier)
Once the data is ingested, we need a place to store it and prepare it for analysis. Google BigQuery is a serverless and highly scalable cloud data warehouse that offers a generous free tier, perfect for this purpose [2].
•Free Tier Capabilities: Up to 1 TB of query processing and 10 GB of active storage per month. These limits are substantial and allow you to store and analyze large volumes of data without incurring initial costs.
•Benefits: BigQuery is known for its speed and ability to handle petabytes of data. It allows you to run complex analyses using standard SQL, making data modeling and report preparation easier.
Essential Tips to Keep BigQuery Costs Low
Although BigQuery offers a free tier, it is crucial to adopt optimization practices to ensure you stay within free limits or minimize costs as your usage grows. BigQuery charges based on the amount of data processed by your queries and the volume of stored data.
1.Medallion Architecture with Views for the Silver Layer: Implement a Medallion architecture (Bronze, Silver, Gold). In the Bronze layer, store raw data. For the Silver layer (cleaned and transformed data), use views instead of materialized or physical tables. Views do not store data; they only define a query, which means you don’t pay for Silver layer storage. Processing happens only when the view is queried, and with query optimization, this can be very efficient.
2.Table Partitioning and Clustering: Partition your tables by time columns (e.g., DATE, TIMESTAMP) and cluster by frequently filtered columns (e.g., user_id, event_id). This allows BigQuery to scan only the relevant data for your queries, significantly reducing the number of bytes processed and, consequently, costs [3].
3.Avoid SELECT *: Always select only the columns you need. SELECT * scans the entire table, which can be expensive on large tables. Use SELECT column1, column2 to optimize processing.
4.Preview Queries: Before running complex queries, use BigQuery’s preview functionality to estimate the amount of data that will be processed. This helps identify and optimize expensive queries before they generate costs.
5.Use LIMIT Carefully: In non-clustered tables, the LIMIT clause does not reduce the amount of scanned data. BigQuery still needs to scan the entire table to apply the limit. Use it only when you know the query is already optimized by partitioning/clustering or for testing on small samples.
6.Remove Obsolete Data: Periodically audit your datasets and remove obsolete or unused data. Although storage is cheap, large volumes of unnecessary data can increase costs in the long run.
7.Use INFORMATION_SCHEMA: Analyze INFORMATION_SCHEMA to understand which columns are most used in filters, sorting, and joins. This can guide your partitioning and clustering decisions to further optimize performance and cost.
3. Visualization and Business Intelligence: Looker Studio, Metabase, or Lightdash
With data ingested and modeled, the final step is making it accessible and understandable for decision-makers. Fortunately, there are excellent visualization and Business Intelligence (BI) tools that are free or open source.
•Looker Studio (formerly Google Data Studio): A free Google tool that integrates natively with BigQuery. It allows you to create interactive dashboards and custom reports with a drag-and-drop interface. It is an excellent option for those already in the Google Cloud ecosystem.
•Metabase: An open-source BI tool that can be self-hosted (requires some infrastructure, but the software is free). It offers a user-friendly interface to create queries, dashboards, and reports, allowing business users to explore data without depending on the data team for every new question.
•Lightdash: Another open-source BI tool that connects directly to your dbt project (if you decide to use it in the future) and your data warehouse. It transforms your dbt model definitions into explorable metrics and dimensions, promoting data governance and self-service.
Why Starting Simple Is the Key
It’s easy to feel overwhelmed by the vast range of tools and technologies in the data space. However, the beauty of a zero-cost modern data stack is that it allows you to start with the essentials, focusing on creating business value as quickly as possible.
There is no need for excessive complexity at the beginning. The core is to establish a reliable data flow, centralized storage, and the ability to visualize insights. This approach allows your team to learn, iterate, and prove the value of data to the organization, building a strong foundation for growth.
As your needs evolve and data becomes more critical, you can gradually introduce more advanced tools (such as dbt for complex transformations or Airflow for orchestration), but always with a solid foundation already in place.
Conclusion: Your Data Journey Starts Now
Building a modern data stack doesn’t have to be an expensive and time-consuming project. With the right tools and a strategic approach, you can start extracting value from your data today, with no upfront cost.
Erathos for ingestion, BigQuery for storage and modeling, and Looker Studio, Metabase, or Lightdash for visualization form a powerful trio that empowers your team to make data-driven decisions, drive innovation, and build a data-oriented culture. Start your journey now and transform how your organization uses its data!
Introduction: Unlocking the Value of Data Without Blowing the Budget
In today’s data-driven landscape, the ability to collect, store, process, and visualize information is crucial for any business seeking innovation and competitive advantage. However, the common perception is that building a modern data stack requires significant investments in software licenses, infrastructure, and specialized resources. But what if we told you it’s possible to start this journey at zero cost, creating a solid foundation for future growth?
This detailed guide will show how data teams can build a robust and efficient stack using free and open-source tools, with a focus on maximizing business value from day one. Our goal is to demystify complexity and cost, proving that you don’t need astronomical budgets to start extracting valuable insights from your data.
The Pillars of Your Free Data Stack
Let’s explore the tools that make up our zero-cost modern data stack, highlighting their capabilities and how they integrate to form a powerful ecosystem.
1. Data Ingestion: Erathos (Free Tier)
The first step in any data journey is ingestion. We need a tool that can collect data from various sources and transport it to our storage environment reliably and efficiently. For this, Erathos offers an ideal solution with its free tier. Erathos already has more than 70 available connectors and allows data to be centralized in BigQuery, Databricks, redshift, S3 Icerberg or postgres.
•Free Tier Capabilities: Up to 1 million monthly rows and 5 pipeline jobs. This is more than enough for many startups and small businesses to begin collecting critical data from their operations, such as application logs, sales data, or user interactions.
•Benefits: Erathos simplifies the creation of data pipelines, allowing you to configure ingestion quickly without the need to write complex code. Its intuitive interface and ability to manage multiple connectors make data collection an accessible task, even for teams with limited resources.
2. Storage and Modeling: Google BigQuery (Free Tier)
Once the data is ingested, we need a place to store it and prepare it for analysis. Google BigQuery is a serverless and highly scalable cloud data warehouse that offers a generous free tier, perfect for this purpose [2].
•Free Tier Capabilities: Up to 1 TB of query processing and 10 GB of active storage per month. These limits are substantial and allow you to store and analyze large volumes of data without incurring initial costs.
•Benefits: BigQuery is known for its speed and ability to handle petabytes of data. It allows you to run complex analyses using standard SQL, making data modeling and report preparation easier.
Essential Tips to Keep BigQuery Costs Low
Although BigQuery offers a free tier, it is crucial to adopt optimization practices to ensure you stay within free limits or minimize costs as your usage grows. BigQuery charges based on the amount of data processed by your queries and the volume of stored data.
1.Medallion Architecture with Views for the Silver Layer: Implement a Medallion architecture (Bronze, Silver, Gold). In the Bronze layer, store raw data. For the Silver layer (cleaned and transformed data), use views instead of materialized or physical tables. Views do not store data; they only define a query, which means you don’t pay for Silver layer storage. Processing happens only when the view is queried, and with query optimization, this can be very efficient.
2.Table Partitioning and Clustering: Partition your tables by time columns (e.g., DATE, TIMESTAMP) and cluster by frequently filtered columns (e.g., user_id, event_id). This allows BigQuery to scan only the relevant data for your queries, significantly reducing the number of bytes processed and, consequently, costs [3].
3.Avoid SELECT *: Always select only the columns you need. SELECT * scans the entire table, which can be expensive on large tables. Use SELECT column1, column2 to optimize processing.
4.Preview Queries: Before running complex queries, use BigQuery’s preview functionality to estimate the amount of data that will be processed. This helps identify and optimize expensive queries before they generate costs.
5.Use LIMIT Carefully: In non-clustered tables, the LIMIT clause does not reduce the amount of scanned data. BigQuery still needs to scan the entire table to apply the limit. Use it only when you know the query is already optimized by partitioning/clustering or for testing on small samples.
6.Remove Obsolete Data: Periodically audit your datasets and remove obsolete or unused data. Although storage is cheap, large volumes of unnecessary data can increase costs in the long run.
7.Use INFORMATION_SCHEMA: Analyze INFORMATION_SCHEMA to understand which columns are most used in filters, sorting, and joins. This can guide your partitioning and clustering decisions to further optimize performance and cost.
3. Visualization and Business Intelligence: Looker Studio, Metabase, or Lightdash
With data ingested and modeled, the final step is making it accessible and understandable for decision-makers. Fortunately, there are excellent visualization and Business Intelligence (BI) tools that are free or open source.
•Looker Studio (formerly Google Data Studio): A free Google tool that integrates natively with BigQuery. It allows you to create interactive dashboards and custom reports with a drag-and-drop interface. It is an excellent option for those already in the Google Cloud ecosystem.
•Metabase: An open-source BI tool that can be self-hosted (requires some infrastructure, but the software is free). It offers a user-friendly interface to create queries, dashboards, and reports, allowing business users to explore data without depending on the data team for every new question.
•Lightdash: Another open-source BI tool that connects directly to your dbt project (if you decide to use it in the future) and your data warehouse. It transforms your dbt model definitions into explorable metrics and dimensions, promoting data governance and self-service.
Why Starting Simple Is the Key
It’s easy to feel overwhelmed by the vast range of tools and technologies in the data space. However, the beauty of a zero-cost modern data stack is that it allows you to start with the essentials, focusing on creating business value as quickly as possible.
There is no need for excessive complexity at the beginning. The core is to establish a reliable data flow, centralized storage, and the ability to visualize insights. This approach allows your team to learn, iterate, and prove the value of data to the organization, building a strong foundation for growth.
As your needs evolve and data becomes more critical, you can gradually introduce more advanced tools (such as dbt for complex transformations or Airflow for orchestration), but always with a solid foundation already in place.
Conclusion: Your Data Journey Starts Now
Building a modern data stack doesn’t have to be an expensive and time-consuming project. With the right tools and a strategic approach, you can start extracting value from your data today, with no upfront cost.
Erathos for ingestion, BigQuery for storage and modeling, and Looker Studio, Metabase, or Lightdash for visualization form a powerful trio that empowers your team to make data-driven decisions, drive innovation, and build a data-oriented culture. Start your journey now and transform how your organization uses its data!